Pagination plays a critical role in how large websites organize and expose content to search engines. Whether it’s ecommerce category listings, blog archives, or directory pages, pagination helps break large datasets into manageable segments that users can navigate easily. At the same time, it directly influences crawl paths, internal link distribution, and index coverage. When implemented correctly, pagination allows search engines like Google to efficiently discover deeper content while preserving strong architectural signals across the site. This guide explains how pagination SEO works, how search engines interpret paginated pages, and the best practices for optimizing pagination in modern technical SEO.
Overview
- Introduction to Pagination SEO
- What Pagination Means in Website Architecture
- How Search Engines Crawl Paginated Pages
- The Evolution of Pagination SEO (From rel=”next/prev” to Modern Signals)
- When Pagination Is Necessary vs When It Should Be Avoided
- Pagination vs Infinite Scroll: SEO Trade-offs
- How Pagination Impacts Crawl Budget
- Pagination and Indexing Strategy
- Internal Linking Signals in Paginated Series
- Canonical Tags in Paginated Content
- Should Paginated Pages Be Indexed or Noindexed?
- Pagination and Duplicate Content Risks
- URL Structure Best Practices for Pagination
- Pagination for Ecommerce Category Pages
- Pagination in Blogs, Archives, and Content Hubs
- Pagination in Faceted Navigation Systems
- Handling Large Paginated Series (100+ Pages)
- Pagination and Core Web Vitals
- Pagination UX vs SEO: Finding the Balance
- Infinite Scroll SEO Implementation (Hybrid Models)
- How Google Treats Paginated Pages Today
- Pagination Optimization Framework (Step-by-Step Implementation)
- Pagination SEO Audit Checklist
- Common Pagination SEO Mistakes
- Real-World Pagination Case Studies
- Pagination Tools for Technical SEO Analysis
- Pagination Best Practices Summary
- Future of Pagination in AI Search Ecosystems
- FAQs
Introduction to Pagination SEO
Pagination is one of those technical SEO topics that looks deceptively simple on the surface. After all, it’s just a sequence of pages, usually labeled “Page 1, Page 2, Page 3,” designed to break long lists of content into manageable sections. Yet from a search engine’s perspective, pagination influences several critical signals simultaneously: crawl paths, index coverage, internal linking distribution, and how ranking equity flows through a site.
Large websites rely heavily on pagination. Ecommerce stores list hundreds or thousands of products across category pages. News sites organize archives by date and topic. Blogs maintain extensive article libraries. Without pagination, these environments would be difficult for users to navigate and nearly impossible for servers to deliver efficiently.
However, pagination also introduces complexity. Each additional page in a paginated sequence becomes a unique URL, often containing near-identical layouts and metadata. Search engines must determine which of these pages deserve indexing, how they relate to each other, and which page best represents the entire content set.
That’s where many SEO problems begin.
Over the years, pagination has been responsible for issues such as crawl budget waste, duplicate content clusters, diluted internal linking signals, and index bloat. In poorly configured systems, search engines may crawl hundreds of pagination URLs without discovering deeper content that actually matters.
From a technical SEO perspective, pagination sits at the intersection of multiple architectural signals:
- crawlability
- internal linking
- canonicalization
- URL parameter management
- indexation control
Because of this, pagination optimization is rarely solved with a single tactic. It requires understanding how search engines interpret sequences of related pages and how those sequences influence overall site architecture.
What Pagination Means in Website Architecture
Pagination refers to the practice of dividing a large set of items or content into multiple pages, each containing a limited number of entries. This approach improves both usability and performance by preventing a single page from becoming excessively long or resource-heavy.
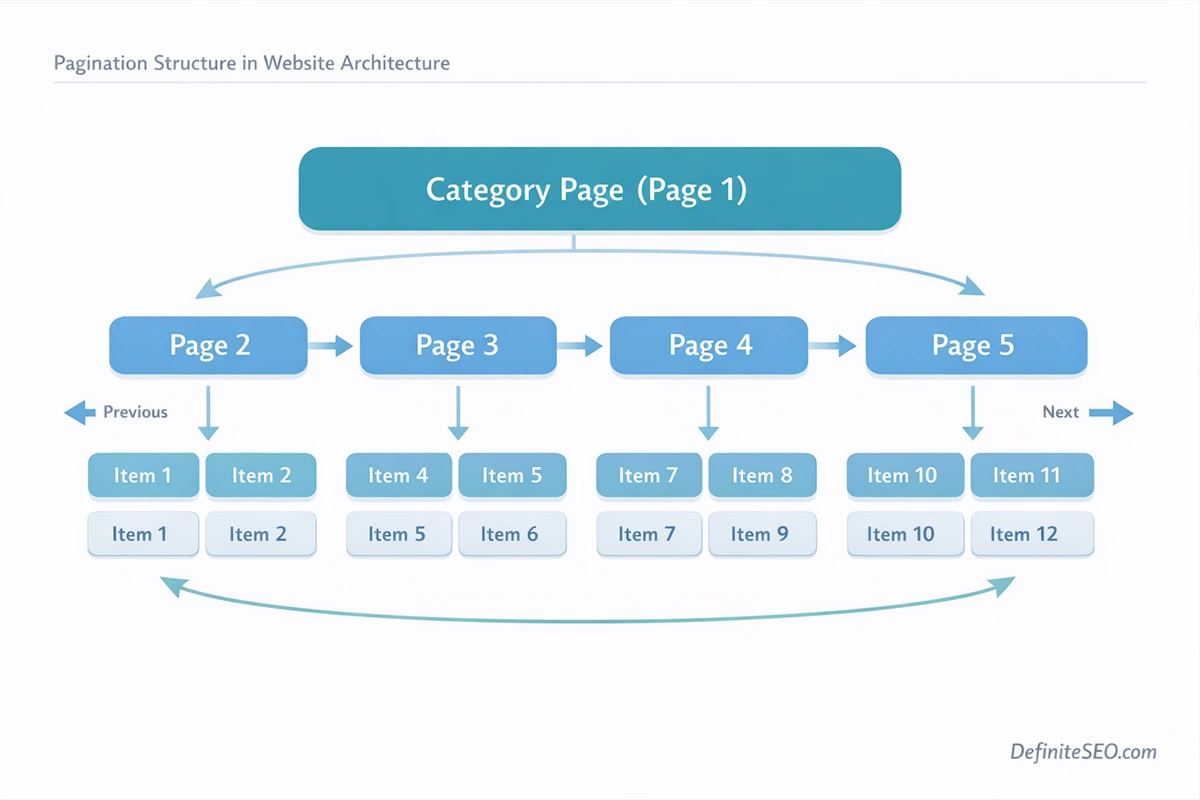
From an architectural perspective, pagination serves as a structural layer within a website. It organizes large datasets into predictable sequences that users and search engines can navigate systematically.
Consider a typical ecommerce category page listing 1,200 products. Loading all products on one page would create a slow, unwieldy interface and likely trigger performance issues. Pagination solves this by distributing products across multiple pages, such as:
/category/
/category/page/2/
/category/page/3/
/category/page/4/
Each page acts as a continuation of the same content set while maintaining a separate URL.
Pagination commonly appears in several types of website structures:
Ecommerce product listings
Online stores frequently display products in sets of 20–40 per page. Pagination allows shoppers to explore entire catalogs without overwhelming page load times.
Blog and article archives
Content-heavy sites often organize posts chronologically or by category. Pagination enables readers to browse older articles without requiring endless scrolling.
Forums and community threads
Discussion platforms divide long conversations into multiple pages to maintain readability and faster rendering.
Directories and marketplaces
Large listings, such as real estate directories or service marketplaces, rely heavily on pagination to organize thousands of entries.
While these use cases may seem straightforward, pagination plays a deeper role in technical SEO because it defines the structural path through which search engines discover content.
Every paginated page contains internal links pointing to the next or previous pages in the sequence. These links create a chain of crawl paths that search engine bots follow when exploring a website.
The deeper the pagination chain becomes, the farther certain items move away from the site’s core internal link structure. If a product or article only appears on page 12 of a category listing, it may take multiple crawl steps for search engines to discover it.
This is why pagination is closely tied to crawl depth, a key factor in how frequently pages are crawled and how easily they are discovered.
Another architectural element worth noting is how pagination interacts with other site systems. In many modern websites, pagination overlaps with:
- filtered product listings
- tag archives
- faceted navigation systems
- parameterized URLs
When these layers combine, pagination structures can multiply rapidly, creating thousands or even millions of potential URLs. Without careful management, this can overwhelm search engine crawlers and dilute ranking signals across many low-value pages.
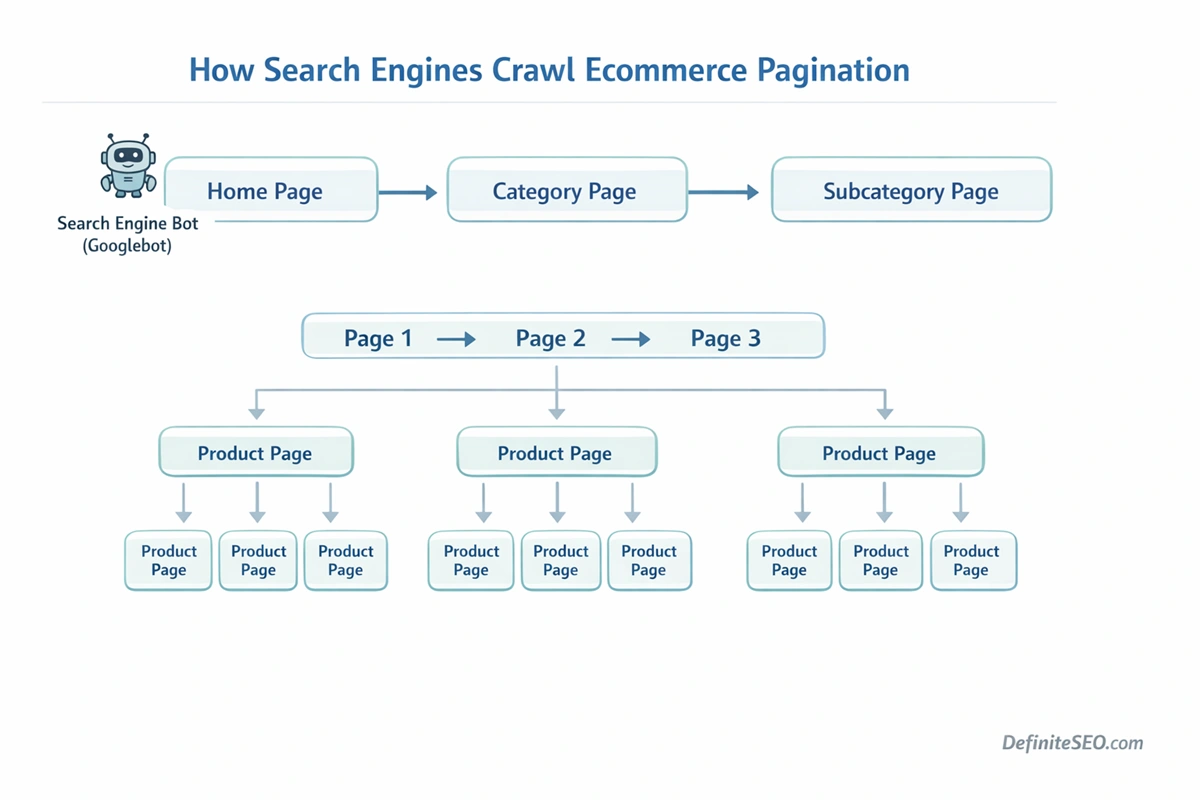
How Search Engines Crawl Paginated Pages
Search engines rely on links to discover content, and pagination creates a predictable pattern of linked pages that bots can follow. When a crawler lands on the first page of a paginated series, it encounters navigation links pointing to subsequent pages. These links form a sequential crawl path that search engines use to explore deeper content.
In its simplest form, the crawling process works like this:
- The crawler discovers Page 1 of a category or archive.
- Page 1 contains a link to Page 2.
- Page 2 links to Page 3.
- The sequence continues until the crawler reaches the end of the series.
While this structure seems logical, it introduces an important technical concept: crawl depth.
Crawl depth refers to the number of clicks required for a search engine to reach a page from the site’s starting point. Pages located deeper within pagination chains may require several hops before a crawler discovers them. The deeper a page sits within the architecture, the less frequently it may be crawled.
For large websites, this can create uneven discovery patterns. Products listed on the first page of a category receive strong internal link signals and frequent crawling. Products buried on page ten or beyond may receive significantly less attention.
Another aspect of pagination crawling involves link equity distribution. Internal links pass authority between pages, and pagination creates a chain where that authority spreads gradually across the sequence. Because the strongest links typically point to the first page of a category, deeper pages tend to receive weaker internal signals.
Search engines therefore must interpret paginated pages as part of a larger group rather than independent pieces of content.
Google’s crawling systems attempt to recognize this relationship by analyzing patterns such as:
- repeated layout structures across pages
- sequential numbering in URLs
- consistent internal linking patterns
- shared page titles and metadata
These signals help search engines identify that a set of pages belongs to the same paginated series.
However, problems arise when pagination structures become extremely deep or when they combine with filtering systems that generate countless variations of the same listing. In such cases, crawlers may encounter vast numbers of URLs that provide minimal new information.
This phenomenon is often called a crawl trap, where bots repeatedly explore pagination sequences without reaching meaningful new content.
Additionally pagination often serves as a discovery mechanism for deeper product or listing pages. When pagination links are removed or misconfigured, those pages may become orphan pages, making them difficult for search engines to crawl and index.
The Evolution of Pagination SEO (From rel=”next/prev” to Modern Signals)
Pagination SEO has changed significantly over the past decade, largely because search engines have evolved in how they interpret page relationships.
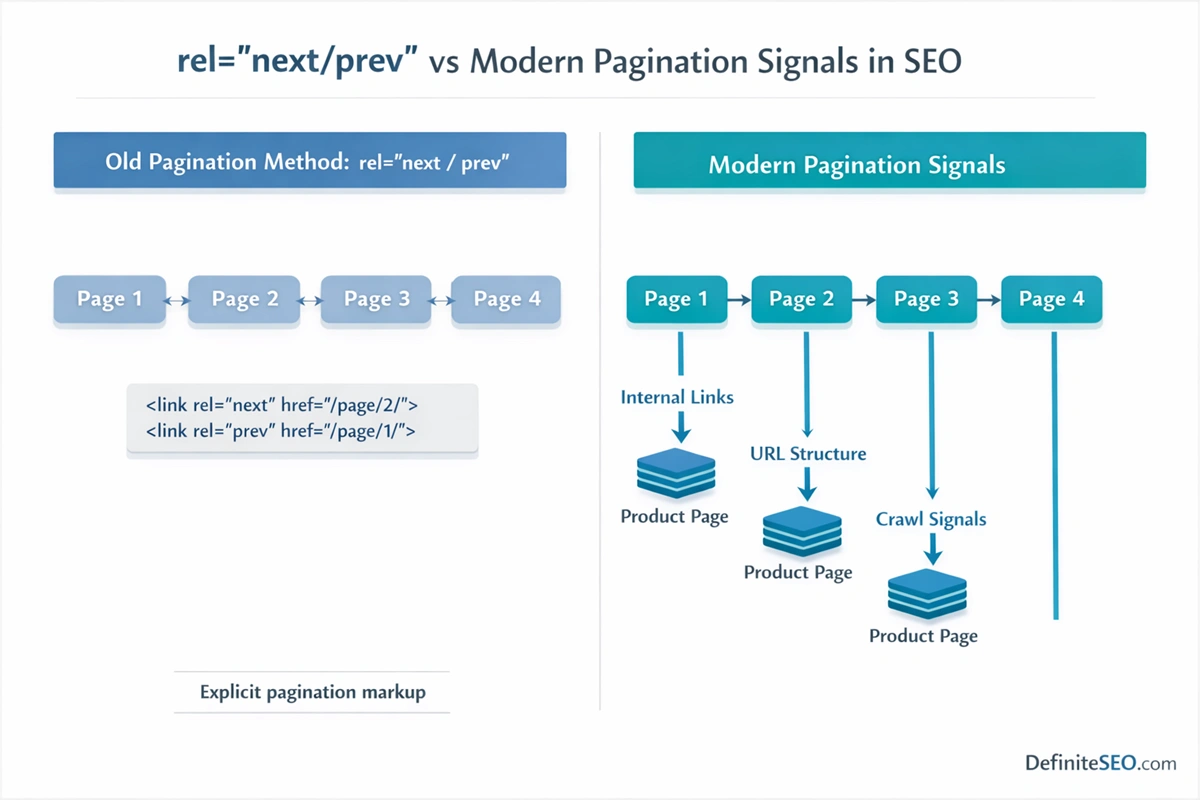
In the early years of modern SEO, Google recommended using two HTML link attributes to help identify paginated sequences:
rel="next"
rel="prev"
These tags were placed in the head section of each paginated page to indicate its position within the series. Page 1 would reference Page 2 as the next page, Page 2 would reference both the previous and next pages, and so on.
The purpose of these signals was to help search engines understand that the pages were connected and should be treated as part of a single content set.
For years, many SEO guides treated rel=”next” and rel=”prev” as essential pagination elements. Website owners were encouraged to implement them to consolidate signals and improve indexing.
Then, in 2019, Google quietly revealed something that surprised the SEO community.
The company announced that it had stopped using rel=”next” and rel=”prev” for several years.
This revelation caused widespread confusion because many websites had invested heavily in implementing these tags. However, the announcement also clarified something important: Google’s crawling and indexing systems had become sophisticated enough to understand pagination relationships without explicit markup.
Instead of relying on rel attributes, modern search engines analyze structural patterns across pages. These patterns include URL structures, link sequences, and consistent page templates.
For example, if a crawler encounters a category page followed by URLs such as:
/category/page/2/
/category/page/3/
/category/page/4/
it can infer that these pages form a sequence.
The shift away from rel=”next/prev” reflects a broader trend in search engine technology. Modern indexing systems rely less on manual hints and more on algorithmic pattern recognition.
When Pagination Is Necessary vs When It Should Be Avoided
Pagination exists primarily to improve usability and performance. When implemented correctly, it helps users navigate large content collections while allowing websites to load pages quickly and efficiently.
There are many scenarios where pagination is not only helpful but essential.
Large ecommerce catalogs are a prime example. An online store with thousands of products cannot realistically display every item on a single page. Pagination ensures that users can browse listings without overwhelming the browser or server.
Similarly, blogs with years of archived content rely on pagination to organize articles by date or category. Without it, older posts would become difficult to locate and navigation would quickly become chaotic.
Forums and discussion platforms also depend heavily on pagination. Long conversation threads are easier to read when divided into smaller segments, allowing participants to jump directly to relevant portions of the discussion.
In these contexts, pagination supports both usability and technical performance.
However, there are situations where pagination introduces more problems than it solves.
One common example is excessive pagination caused by low item counts per page. If a category displays only five products per page despite containing hundreds of items, the pagination chain becomes unnecessarily deep. This increases crawl depth and spreads internal link equity thinly across many pages.
Another issue occurs when pagination combines with dynamic filters. For instance, an ecommerce category with filters for color, brand, size, and price may generate thousands of filtered views. If each of those filtered views also produces paginated sequences, the total number of crawlable URLs can explode dramatically.
In these cases, pagination becomes part of a larger structural challenge involving faceted navigation and parameter management.
There are also situations where alternative approaches may work better than traditional pagination. Infinite scroll interfaces, load-more buttons, and hybrid navigation systems can provide smoother user experiences while still preserving crawlable URLs in the background.
The key is balance.
Pagination should exist where it genuinely improves navigation and performance. At the same time, it should not generate unnecessary URL complexity or dilute important ranking signals.
Pagination vs Infinite Scroll: SEO Trade-offs
Modern websites increasingly experiment with infinite scroll interfaces. Instead of dividing content into numbered pages, infinite scroll continuously loads additional items as users move down the page. Social media feeds, news aggregators, and many ecommerce stores use this approach because it creates a seamless browsing experience.
From a user perspective, infinite scroll often feels faster and more natural. Visitors can keep exploring products or articles without clicking “Next Page.” Engagement metrics sometimes improve because users encounter more content without friction.
Yet from a technical SEO standpoint, infinite scroll introduces several challenges.
Search engines primarily discover content through links. Traditional pagination creates clear links between pages, forming predictable crawl paths. Infinite scroll, on the other hand, often loads content dynamically through JavaScript as the user scrolls. If that content does not exist on crawlable URLs, search engines may never discover it.
This creates a visibility problem. The first set of items on a page might be indexed and ranked, while deeper items remain effectively hidden from search engines.
Google has repeatedly clarified that infinite scroll is not inherently bad for SEO. The key requirement is that the content loaded through scrolling must also be accessible through paginated URLs. In other words, infinite scroll should function as a visual layer on top of a crawlable pagination structure.
A common implementation approach involves loading additional content dynamically while updating the browser URL using the History API. As the user scrolls, the interface may simulate moving to /page/2, /page/3, and so on. Behind the scenes, these pages still exist as independent URLs that search engines can crawl.
When implemented this way, the website benefits from both usability and crawlability.
The problem arises when infinite scroll is implemented without a fallback structure. If the site relies entirely on dynamic loading with no underlying pagination, search engines may only see the first portion of the content.
This is why hybrid models have become increasingly popular. In these systems:
- Users experience smooth infinite scrolling
- Search engines crawl a traditional paginated structure
The hybrid approach preserves discoverability while improving user interaction.
I often note that during technical audits, infinite scroll issues frequently surface on modern ecommerce themes where developers prioritized user experience but overlooked crawl accessibility. Restoring crawlable pagination behind the infinite scroll interface often leads to improved product discovery in search results.
Ultimately, pagination and infinite scroll are not competing technologies. The most effective strategy often combines both, allowing the interface to feel fluid while maintaining a clear architecture for search engines.
How Pagination Impacts Crawl Budget
Crawl budget refers to the number of pages a search engine crawler is willing to fetch from a website within a given period. While smaller websites rarely need to worry about crawl limits, large sites with thousands or millions of URLs must carefully manage how search engines spend their crawl resources.
Pagination plays a significant role in this process.
Each page in a paginated sequence represents a separate URL. On its own, this is not problematic. A category with ten pagination pages is relatively easy for search engines to crawl and understand.
The complexity appears when pagination interacts with other structural features such as filters, parameters, and sorting options. A single category might generate dozens of variations:
- different sorting orders
- filtered product sets
- parameterized URLs
- combinations of multiple filters
If each variation also includes pagination, the number of crawlable URLs can multiply dramatically.
Imagine an ecommerce category with:
- 20 pagination pages
- 5 color filters
- 5 brand filters
- 3 sorting options
The potential number of crawlable URLs can quickly reach hundreds or even thousands. Many of these URLs contain overlapping or low-value content, yet search engine crawlers may still attempt to explore them.
This scenario leads to inefficient crawl budget allocation. Instead of focusing on high-value pages such as product pages or core category pages, crawlers spend time navigating endless pagination variations.
Another important factor is pagination depth.
When a crawler lands on Page 1 of a category, it must follow sequential links to reach deeper pages. If a site contains very long pagination chains, such as 100 or more pages, some content may be several steps removed from the main internal link structure.
Pages buried deep within pagination sequences may receive fewer crawl visits, particularly if search engines detect that the content adds little new information compared to earlier pages.
This is why pagination should always be evaluated in relation to crawl efficiency. Well-designed pagination helps crawlers explore content logically. Poorly managed pagination, especially when combined with faceted navigation, can lead to massive crawl waste.
In enterprise environments, log file analysis often reveals how Googlebot behaves within pagination structures. SEO teams frequently observe that crawlers repeatedly explore early pagination pages while rarely reaching deeper levels where additional content exists.
Improving pagination structure, limiting unnecessary parameter combinations, and strengthening internal linking pathways can significantly improve crawl efficiency across large sites.
Pagination and Indexing Strategy
One of the most debated questions in technical SEO is whether paginated pages should be indexed or not indexed.
At first glance, it may seem logical to prevent indexing for pages such as /page/2/ or /page/3/, since these pages often contain content similar to Page 1. Some SEO practitioners historically recommended using the noindex directive on paginated pages to reduce index bloat.
However, this approach can create unintended consequences.
Search engines rely on paginated pages to discover deeper items within a listing. If pagination pages are removed from the index and eventually dropped from crawling pathways, some content may become harder for search engines to discover.
For example, imagine a category page displaying 20 products per page. If the category contains 200 products, many of those items will only appear on deeper pagination pages. Blocking those pages from indexing could weaken the internal discovery path for those products.
Google’s current guidance generally leans toward allowing paginated pages to remain crawlable and indexable, especially when they contribute to content discovery.
That said, not every pagination page needs to rank in search results.
Search engines typically select a representative page within a paginated series, often Page 1, because it provides the strongest overview of the content set. Deeper pages may still exist in the index but rarely rank independently unless they contain unique content or valuable internal links.
An effective pagination indexing strategy therefore focuses on maintaining crawl accessibility while allowing search engines to determine which pages deserve visibility in search results.
There are also situations where selective indexing control may be useful. Extremely large pagination chains with hundreds of pages may contain diminishing value beyond a certain depth. In such cases, technical SEO teams sometimes implement strategies that limit indexation while preserving crawl paths.
The goal is not to remove pagination entirely from the index but to maintain a balanced index structure where high-value pages receive the strongest signals.
Internal Linking Signals in Paginated Series
Internal linking is one of the most powerful signals search engines use to understand website structure. Pagination introduces a unique internal linking pattern because each page in the series links to both adjacent pages and the items contained within the listing.
These links form a chain that distributes authority throughout the sequence.
The first page of a category typically receives the strongest internal link signals. It is usually linked from the main navigation, internal category hubs, or sitemap pages. Because of this, Page 1 tends to accumulate the majority of link equity.
As the pagination sequence continues, each subsequent page receives progressively weaker signals because it is further removed from the site’s primary linking structure.
This phenomenon is sometimes referred to as Page 1 dominance.
In many websites, Page 1 receives strong internal links and may rank for category-level keywords. Meanwhile, deeper pages exist primarily to expose additional items rather than compete for rankings themselves.
However, deeper pagination pages still play an important role in internal linking.
Every item listed on a pagination page typically links to its corresponding detail page, such as a product page or article. These links help search engines discover and crawl those deeper content assets.
The structure effectively acts as a distribution network. Category pages funnel link equity to listing pages, which then pass signals to the individual content pages.
If pagination chains become excessively deep, this distribution weakens. Products or articles appearing on Page 15 or Page 20 may receive significantly weaker internal link signals compared to items on earlier pages.
To mitigate this issue, some websites introduce additional internal linking mechanisms. These may include related product sections, featured content modules, or cross-category recommendations that provide alternative discovery paths.
Another architectural approach involves strengthening category hub pages that link to important subcategories or curated collections. These hubs reduce reliance on deep pagination as the only discovery pathway.
Canonical Tags in Paginated Content
Canonical tags help search engines understand which version of a page should be treated as the primary representation when multiple similar pages exist. Because paginated pages often share similar layouts, metadata, and content structures, canonicalization becomes an important part of pagination SEO.
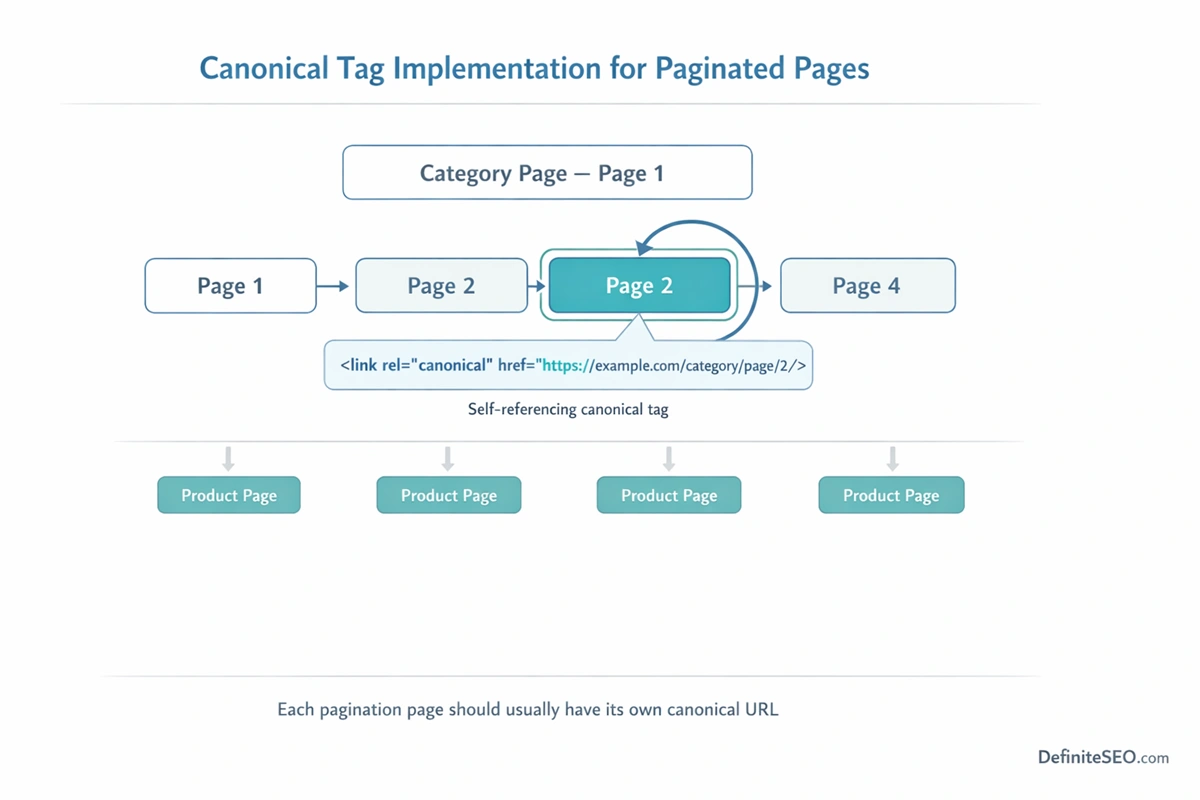
One of the most common mistakes involves canonicalizing every pagination page to the first page of the series.
At first glance, this approach might appear logical. Since Page 1 represents the beginning of the listing, some developers assume that all subsequent pages should point back to it as the canonical version.
In reality, this configuration can cause problems.
When Page 2, Page 3, and other pages canonicalize to Page 1, search engines may treat them as duplicates and ignore them entirely. As a result, the crawler may not fully process the content appearing on those deeper pages. Products or articles located there could become more difficult for search engines to discover and index.
The recommended approach is typically self-referencing canonical tags. If you still want to set the first page as a canonical page you can use our DefiniteSEO WordPress Plugin.
In this configuration, each paginated page includes a canonical tag pointing to its own URL. Page 1 canonicalizes to itself, Page 2 canonicalizes to itself, and so on. This signals to search engines that each page is a legitimate part of the sequence rather than a duplicate of another page.
Self-referencing canonicals preserve the integrity of the pagination chain while still allowing search engines to determine which page should rank for broad queries.
Canonicalization also plays an important role when pagination interacts with parameterized URLs. Filters, sorting options, and session parameters can generate multiple URL variations for the same pagination page. Proper canonical tags help consolidate these variations and prevent unnecessary duplication.
For example, a filtered URL such as:
/category?page=2&sort=price
might canonicalize to the clean version:
/category/page/2/
This ensures that ranking signals accumulate on the preferred URL while avoiding fragmentation across multiple parameter combinations.
Should Paginated Pages Be Indexed or Noindexed?
Few topics in technical SEO generate as much confusion as the question of whether paginated pages should be indexed. For years, many SEO practitioners recommended applying the noindex directive to pagination pages in order to prevent them from appearing in search results. The reasoning was straightforward: these pages often contain similar layouts, repetitive metadata, and only partial subsets of a larger content collection.
At first glance, removing them from the index seems like a clean solution.
In practice, however, the issue is more nuanced. Paginated pages frequently serve as important discovery paths for deeper content within a site. When search engines crawl Page 1 of a category or archive, they rely on pagination links to reach Page 2, Page 3, and beyond. Those deeper pages often contain items that may not appear anywhere else in the site’s internal linking structure.
If pagination pages are aggressively set to noindex, they can gradually lose their importance within the crawl ecosystem. Search engines may continue to crawl them for a while, but over time they might treat them as lower-priority resources. When that happens, the discovery pathway to deeper items becomes weaker.
Consider a category containing 300 products displayed across 15 pages. If only Page 1 is indexable and the rest are marked noindex, products listed on Page 10 or Page 12 may become harder for search engines to find quickly.
Modern search engines are generally capable of recognizing pagination patterns and selecting the most representative page for ranking purposes. In most cases, that representative page is the first page of the series because it provides the strongest overview of the listing.
This means paginated pages can remain indexable without necessarily competing in search results. Search engines often index them as part of the site structure while choosing not to display them prominently for broad queries.
There are scenarios where selective indexing control can make sense. Very large sites with thousands of paginated URLs may wish to limit index bloat by controlling how deeply pagination pages are indexed. But even in those cases, the strategy must be implemented carefully to ensure that crawl paths remain intact.
During technical SEO audits, I frequently observes that overuse of noindex directives on pagination pages can create unintended discovery issues. The problem is rarely visible at first. Pages continue to function normally for users, yet the underlying crawl structure gradually weakens.
For most websites, the safest and most sustainable strategy is simple: allow paginated pages to remain crawlable and indexable, while focusing optimization efforts on the primary category or archive pages that serve as entry points for search traffic.
Pagination and Duplicate Content Risks
Pagination naturally produces pages that look similar. Each page in a series often shares the same template, navigation elements, headings, and metadata. The primary difference between pages is usually the set of items being displayed.
Because of this structural similarity, pagination is often mistakenly associated with duplicate content problems.
In reality, pagination does not automatically create harmful duplication. Search engines expect to encounter paginated sequences on large websites and are generally capable of understanding that these pages belong to the same content set.
However, duplicate content issues can arise when pagination is implemented poorly or when additional signals create unnecessary repetition across pages.
One common issue involves metadata duplication. If every paginated page uses the exact same title tag and meta description, search engines may struggle to distinguish them. While this does not necessarily lead to penalties, it can reduce clarity about the role each page plays within the site.
Another challenge appears when the visible content across pagination pages overlaps heavily. For instance, if product listings repeat across several pages due to sorting variations or filtering combinations, the resulting URLs may contain nearly identical content.
Faceted navigation systems often exacerbate this issue. A single category page might generate dozens of filtered views, each containing its own pagination chain. When these filtered pages display similar item combinations, the site may end up producing large clusters of near-duplicate URLs.
Search engines must then determine which version represents the primary page. In some cases, this can dilute ranking signals across multiple URLs rather than consolidating them.
The key to preventing pagination-related duplication lies in maintaining clear structural signals.
Consistent internal linking patterns, logical URL structures, and proper canonicalization help search engines understand that paginated pages belong to a series rather than existing as competing duplicates.
Another helpful practice involves introducing subtle variations in metadata for paginated pages. For example, including page numbers within title tags can provide additional context. Instead of repeating the same title across all pages, a title such as “Running Shoes – Page 2” clarifies the page’s position within the sequence.
These small structural signals reinforce the relationship between pages and make it easier for search engines to interpret pagination correctly.
URL Structure Best Practices for Pagination
URL structure plays a crucial role in how search engines interpret paginated content. Clear, predictable URLs help crawlers recognize pagination sequences and understand the relationships between pages.
The most effective pagination URLs follow a logical pattern that reflects the order of the sequence. For example:
/category/
/category/page/2/
/category/page/3/
This format communicates several useful signals simultaneously. It indicates that Page 2 and Page 3 belong to the category page and that they follow a clear numerical progression.
Many websites instead rely on parameter-based pagination such as:
/category?page=2
While parameter-based structures can work, they introduce additional complexity. Parameters can interact with other URL variables such as sorting options, filters, or tracking parameters. This can lead to multiple URL variations representing the same pagination page.
For example:
/category?page=2&sort=price
/category?page=2&color=black
/category?page=2&sessionid=123
Without proper canonicalization or parameter handling, these variations can create duplicate URLs that fragment signals and consume crawl resources.
Folder-based pagination structures generally provide clearer signals and are easier for both search engines and users to interpret. They also reduce the likelihood of unnecessary parameter combinations.
Another important consideration involves preventing infinite pagination loops. Certain poorly configured systems allow pagination numbers to extend indefinitely, generating URLs such as /page/9999/ even when no additional content exists. Crawlers may attempt to explore these URLs, wasting valuable crawl budget.
Pagination URLs should always correspond to real content boundaries.
Consistency also matters. Switching between different pagination formats across the site can create confusion for crawlers. A blog that uses /page/2/ in one section and ?page=2 in another may inadvertently create mixed signals about how pagination works within the architecture.
Pagination for Ecommerce Category Pages
Ecommerce websites depend heavily on pagination because product catalogs often contain hundreds or thousands of items. Category pages serve as gateways to these catalogs, allowing users to explore product collections through structured listings.
Pagination ensures that these listings remain manageable from both a usability and performance perspective.
Most ecommerce platforms display between 20 and 40 products per page. This balance helps maintain fast loading times while presenting enough items for shoppers to browse comfortably.
From an SEO standpoint, the first page of a category typically becomes the most important page in the sequence. It receives the strongest internal links, often appears in site navigation menus, and usually targets the primary category keyword.
For example, the first page of a category such as “Running Shoes” may be optimized to rank for that exact query. Subsequent pages exist primarily to expose additional products rather than compete for the same keyword.
However, deeper pagination pages still play a vital role in product discovery. Products listed on Page 5 or Page 8 may not appear on the first page but can still rank individually through their product pages.
If pagination is poorly configured, those deeper products may receive weaker internal linking signals. Over time, this can reduce their visibility in search results.
Large ecommerce websites therefore need to carefully manage pagination depth. Categories with thousands of products can easily generate dozens of pagination pages, which may push some items far away from the main internal linking structure.
Some stores address this issue by strengthening cross-linking within product pages. Related product sections, “customers also viewed” modules, and curated product collections create additional discovery pathways that complement pagination.
Another important consideration involves the interaction between pagination and product filters. Filters for attributes such as size, color, brand, and price can generate countless category variations. When each filtered view includes its own pagination sequence, the number of crawlable URLs increases dramatically.
Managing this complexity requires coordination between pagination strategy, faceted navigation controls, and canonical signals.
Pagination in Blogs, Archives, and Content Hubs
While ecommerce sites rely on pagination for product listings, content-driven websites use it primarily to organize large archives of articles. Blogs, news platforms, and knowledge bases often publish content continuously, creating extensive libraries that must remain navigable for readers.
Pagination helps divide these libraries into manageable segments.
A typical blog archive might display ten or fifteen articles per page. As new posts are published, older content gradually moves to deeper pagination pages. Over time, these archives may extend to dozens of pages, particularly for sites with long publishing histories.
From an SEO perspective, the first page of a blog category or archive usually serves as the primary landing page for search queries related to that topic. It contains the most recent or most relevant articles and often receives the strongest internal links from the site’s navigation.
Deeper archive pages function mainly as discovery pathways for older content. They ensure that search engines and users can still reach articles that are no longer visible on the first page.
This structure can be particularly valuable for evergreen content libraries. Educational blogs, technical documentation sites, and tutorial hubs often contain articles that remain relevant for years. Pagination ensures that these older resources remain accessible within the site architecture.
WordPress and similar content management systems automatically generate paginated archives for categories, tags, and author pages. While these features simplify content organization, they can also introduce complexity if not managed properly.
For example, tag archives may create multiple paginated listings that contain overlapping article sets. When these pages grow large, they can produce extensive pagination chains that contribute little unique value.
In such cases, it may be useful to evaluate which archive structures truly serve readers and which ones simply duplicate navigation pathways.
Content hubs represent another interesting use of pagination. Some websites organize large collections of resources around central topic pages. These hubs may contain curated content sections followed by paginated lists of related articles.
When designed thoughtfully, this structure allows the hub page to function as a topical authority signal while pagination exposes the full depth of the content library.
Pagination in Faceted Navigation Systems
Faceted navigation introduces one of the most complex technical SEO environments where pagination operates. On large ecommerce and directory websites, users often refine listings using filters such as brand, color, size, price range, rating, or availability. Each combination of filters creates a new view of the product catalog.
When pagination is layered on top of this system, the number of possible URLs can expand rapidly.
Imagine a category page listing 500 products. If the category allows filtering by five brands, four colors, three sizes, and two price ranges, the total number of filtered combinations grows quickly. Each filtered view may contain its own paginated sequence of pages.
The result is a massive network of URLs such as:
/shoes/?brand=nike&page=2
/shoes/?brand=nike&color=black&page=3
/shoes/?size=10&price=under-100&page=4
Every additional filter multiplies the potential number of paginated pages.
From a user perspective, faceted navigation is extremely useful. It allows shoppers to narrow large catalogs down to the exact items they want. For search engines, however, the situation becomes much more complicated. Crawlers may attempt to explore every possible combination of filters and pagination levels, even though many of those URLs contain overlapping or low-value content.
This phenomenon is sometimes described as URL explosion. The number of crawlable pages increases dramatically, yet the actual content value across those pages changes very little.
Pagination plays a central role in this process because it extends every filtered view into a series of additional pages. A single filter may create ten or more paginated URLs, each containing slightly different product listings.
If this structure is left uncontrolled, search engines may waste significant crawl resources exploring filtered pagination paths rather than focusing on core category pages and product detail pages.
Managing pagination within faceted navigation requires careful coordination between multiple technical signals. Canonical tags, crawl directives, parameter handling, and internal linking strategies all influence how search engines interpret these URLs.
In many enterprise ecommerce environments, SEO teams choose to allow indexing only for carefully selected filter combinations that align with real search demand. Other combinations remain crawlable for users but are consolidated through canonical signals or parameter handling rules.
Handling Large Paginated Series (100+ Pages)
Pagination becomes particularly challenging when a content set grows extremely large. Some ecommerce categories contain thousands of products, while long-running forums or content archives may span hundreds of pages. In these situations, pagination chains can extend far beyond the typical range of ten or twenty pages.
A category with 2,000 products might easily generate 100 pagination pages if each page displays 20 items.
From a technical SEO perspective, very deep pagination introduces two key challenges: crawl depth and internal signal dilution.
Search engines generally begin crawling a site from pages that receive strong internal links, such as the homepage or primary category pages. As crawlers move deeper through pagination sequences, each additional step represents another layer of distance from the core architecture.
Pages located far down the sequence may receive less frequent crawling. If a crawler must navigate through ten or fifteen intermediate pages to reach certain products, those products may be discovered more slowly or revisited less often.
Another consequence involves the distribution of internal linking signals. As link equity flows through pagination chains, the strength of those signals tends to weaken with each step. Content located on extremely deep pagination pages may therefore receive minimal internal authority compared to items appearing earlier in the sequence.
This does not mean that large paginated series should be eliminated. For many websites, they are unavoidable. Instead, the goal is to ensure that important content does not rely exclusively on deep pagination for discovery.
Several architectural approaches can help reduce these limitations. One method involves strengthening category hubs and subcategory structures so that products are grouped into more specific collections. Rather than placing thousands of products in a single category, the site may create multiple thematic or functional subcategories that reduce pagination depth.
Another approach involves introducing cross-linking mechanisms within product pages. Related product modules, curated collections, and “customers also viewed” sections create additional pathways that connect products across the catalog.
These internal links reduce reliance on long pagination chains and help distribute authority more evenly throughout the site.
Large-scale pagination structures also benefit from periodic auditing. Technical SEO teams often use crawling tools or log file analysis to identify how far search engine bots typically travel within pagination sequences. If crawlers rarely reach beyond a certain depth, architectural adjustments may be necessary to improve discoverability.
Pagination and Core Web Vitals
Pagination influences website performance in several subtle ways, particularly when it comes to Core Web Vitals metrics. Because paginated pages typically display lists of items, products, articles, or listings, the number of elements loaded on each page can significantly affect loading speed and rendering performance.
The first metric often affected is Largest Contentful Paint (LCP). Category pages containing large product grids, high-resolution images, and multiple interactive elements may take longer to render the main content area. If too many items appear on a single page, the browser must download and process a large number of resources before the page becomes fully visible.
Pagination helps manage this load by limiting the number of items displayed at once. A page displaying 20 products typically loads much faster than a page attempting to display 200 products simultaneously.
Another performance factor involves Cumulative Layout Shift (CLS). Many ecommerce layouts dynamically load product images or promotional elements after the initial page render. If image dimensions are not properly reserved in the layout, these elements can cause visible shifts that negatively affect the user experience.
Paginated pages that load many product thumbnails are especially susceptible to this issue. Ensuring that image sizes are defined in advance helps stabilize the layout as content loads.
Interaction to Next Paint (INP) can also be affected by pagination structures. Large listing pages with extensive filtering tools, sorting options, and interactive elements may introduce delays when users interact with the interface. Efficient JavaScript execution and optimized event handling become important for maintaining responsive interactions.
Another performance technique often used on paginated pages is lazy loading. Instead of loading every product image immediately, the browser loads images only when they approach the visible portion of the screen. This reduces initial page weight and improves perceived loading speed.
While lazy loading improves performance, it must be implemented carefully to ensure that search engines can still access important content. Images and product links should remain visible within the HTML structure rather than relying entirely on dynamic loading.
Pagination therefore serves as both a navigation mechanism and a performance management tool. By distributing large content collections across multiple pages, websites can maintain faster loading times and better user experience metrics.
Pagination UX vs SEO: Finding the Balance
Pagination sits at the intersection of two sometimes competing priorities: user experience and search engine optimization. Designers and developers often prioritize smooth browsing experiences, while SEO specialists focus on crawlability, internal linking, and index management.
The challenge is to balance these priorities in a way that benefits both users and search engines.
From a usability standpoint, pagination should make it easy for visitors to explore content collections without feeling overwhelmed. Clear navigation controls, visible page numbers, and logical ordering help users move through listings efficiently.
Many ecommerce sites provide several pagination controls simultaneously. Users may click numbered pages, jump directly to a specific page, or use “next” and “previous” buttons. These options allow visitors to navigate listings in a way that matches their browsing behavior.
At the same time, pagination must preserve logical internal linking pathways for search engines. Each pagination page should link clearly to adjacent pages in the sequence so that crawlers can move through the listing without encountering dead ends.
Problems often arise when design decisions prioritize aesthetics at the expense of crawlability. For example, some modern interfaces hide pagination links behind JavaScript interactions or replace them entirely with dynamic loading mechanisms. While these interfaces may appear sleek, they can create barriers for search engine crawlers.
Another UX consideration involves the number of items displayed per page. Showing too few items may require users to navigate through dozens of pages to find relevant content. Showing too many items may slow down page performance and overwhelm visitors.
Most successful implementations strike a balance between these extremes, typically displaying between 20 and 40 items per page depending on the type of content.
Pagination should also provide clear context about where the user is within the sequence. Visual indicators such as highlighted page numbers or progress indicators help users understand how far they have navigated within the listing.
Infinite Scroll SEO Implementation (Hybrid Models)
As discussed earlier, infinite scroll interfaces have become increasingly common across modern websites. Users appreciate the seamless experience of scrolling through content without repeatedly clicking pagination links. However, pure infinite scroll implementations can create serious crawlability challenges if they hide content behind dynamic loading mechanisms.
To solve this problem, many websites implement hybrid pagination models.
In a hybrid model, the user interface behaves like infinite scroll while the underlying architecture maintains a traditional paginated structure. As users scroll down the page, additional content loads dynamically, giving the impression of a continuous feed.
Behind the scenes, however, each portion of content corresponds to a real paginated URL.
When the user scrolls past a certain threshold, the browser may update the URL to represent the next page in the sequence. For example, scrolling through a category page might gradually update the address bar from /page/1/ to /page/2/ and then /page/3/.
This technique relies on browser features such as the History API to modify URLs without triggering a full page reload. From the user’s perspective, the experience remains smooth and uninterrupted.
Search engines, meanwhile, can crawl the individual paginated URLs directly. Each page exists as a standalone document that contains a subset of the listing, ensuring that all items remain discoverable.
Hybrid pagination systems therefore combine the strengths of both approaches. They maintain crawlable architecture for search engines while delivering modern browsing experiences for users.
Implementing this model requires careful technical coordination. Developers must ensure that each paginated URL returns a fully functional page when accessed directly. Content should not depend entirely on JavaScript events that only trigger during scrolling.
Another important consideration involves internal linking. Even though users may interact with an infinite scroll interface, the HTML structure should still include traditional pagination links that search engines can follow.
How Google Treats Paginated Pages Today
Search engines have become far more sophisticated in understanding paginated content than they were a decade ago. Early SEO practices relied heavily on explicit hints such as rel="next" and rel="prev" attributes to signal relationships between pages in a sequence. As discussed earlier, Google eventually revealed that it had stopped using these signals years before publicly announcing the change.
Today, Google primarily relies on structural patterns within a website to interpret paginated content.
When Googlebot encounters a listing page, it evaluates several signals to determine whether that page is part of a paginated series. These signals include consistent URL patterns, sequential numbering within URLs, repeated layout structures, and internal links that connect pages in a predictable order.
If a crawler detects links such as “Next,” “Previous,” or numbered pagination controls, it can infer that the pages belong to a continuous listing. This recognition allows Google to treat the sequence as a related group rather than a set of unrelated pages.
In many cases, Google attempts to select a representative page from the series that best reflects the entire content set. For category listings or blog archives, this representative page is often the first page because it usually contains the most prominent items and receives the strongest internal linking signals.
However, deeper pagination pages can still be indexed and crawled. Their primary role is often to expose additional content rather than compete for broad search queries.
Google’s systems also analyze how internal links distribute authority across paginated sequences. If a site links heavily to the first page of a category but provides weaker signals for deeper pages, Google may interpret those deeper pages as secondary navigational resources.
Another factor influencing how pagination is treated involves content uniqueness. If a deeper pagination page contains distinctive or valuable items that are not easily discoverable elsewhere on the site, Google may still crawl and index it actively.
Log file analysis often provides valuable insights into this behavior. During large-scale SEO audits, I’ve observed that Googlebot typically crawls the first few pages of pagination sequences most frequently. As page depth increases, crawl frequency often declines unless the deeper pages contain strong internal links or important content.
Pagination Optimization Framework (Step-by-Step Implementation)
Optimizing pagination is rarely about applying a single technical fix. Instead, it requires a structured approach that evaluates how pagination interacts with the broader architecture of a website.
A systematic framework can help identify weaknesses in pagination structure and guide improvements.
Step 1: The first step involves identifying all paginated page types across the website. These may include product categories, blog archives, search result pages, directories, and filtered listings. Understanding where pagination exists provides the foundation for evaluating how it affects crawl behavior.
Step 2: Once these pages are identified, the next step is to analyze how search engines crawl them. Tools such as crawling software, server log analysis, and search console data can reveal whether bots are reaching deeper pagination levels or repeatedly crawling only the earliest pages.
If crawlers rarely reach deeper pages, the site may need stronger internal linking signals or improved structural pathways.
Step 3: After crawl patterns are understood, the next focus should be indexing strategy. Pagination pages should remain accessible to search engines, but the site should ensure that primary entry pages such as category hubs or archive landing pages receive the strongest optimization signals. These pages typically serve as the main ranking targets for category-level queries.
Key Consideration:
The framework should also evaluate canonicalization and URL consistency. Pagination pages should generally use self-referencing canonical tags while consolidating parameter variations that represent the same content.
Clear URL patterns help search engines recognize pagination sequences and prevent duplication caused by parameter combinations.
Internal linking structure represents another key step in the framework. Pagination links should form a logical sequence that allows both users and search engines to move through the listing efficiently. At the same time, deeper content should not rely exclusively on pagination for discovery.
Supporting internal links from related content, featured sections, or category hubs can strengthen the overall architecture.
Finally, ongoing monitoring ensures that pagination remains efficient as the site grows. Large ecommerce stores or content platforms continuously add new items, which can extend pagination sequences over time. Periodic audits help confirm that the structure continues to support efficient crawling and discovery.
I often emphasize that pagination optimization works best when treated as part of a broader technical SEO ecosystem. Crawl budget management, internal linking strategy, canonicalization, and URL design all intersect with pagination behavior.
Pagination SEO Audit Checklist
A comprehensive pagination audit evaluates how pagination affects crawlability, indexing, and internal linking across a website. Rather than focusing on a single element, the audit should examine how multiple signals interact within the architecture.

The first area to evaluate is crawlability. Pagination links should be accessible within the HTML structure so that search engine crawlers can follow them naturally. If pagination relies heavily on JavaScript interactions without crawlable links, search engines may struggle to discover deeper pages.
Next, the audit should examine how paginated pages are indexed. SEO teams should verify whether search engines are indexing these pages and how they appear in search results. If deeper pagination pages are unexpectedly dominating search results, it may indicate that category-level pages lack sufficient optimization signals.
Canonical implementation is another critical component of the audit. Each pagination page should typically contain a self-referencing canonical tag that confirms it as the preferred version of that specific page. Parameterized variations should point toward the clean canonical version to prevent duplication.
Internal linking structure should also be analyzed carefully. Pagination pages must link clearly to adjacent pages while also passing link equity to the individual items listed within them. Weak internal linking patterns can limit the discoverability of deeper content.
URL parameters deserve particular attention during audits, especially on ecommerce sites with filtering systems. Pagination URLs that combine multiple parameters can create large numbers of crawlable pages with overlapping content. Parameter handling strategies may be needed to prevent unnecessary crawl expansion.
Performance metrics should also be reviewed. Paginated pages often contain large content grids, making them vulnerable to slow loading times or layout instability. Monitoring Core Web Vitals ensures that pagination pages maintain strong performance.
Finally, the audit should evaluate the overall depth of pagination chains. Extremely deep sequences may indicate that content organization could be improved through subcategories, hubs, or alternative navigation pathways.
A thorough pagination audit often reveals structural insights that extend far beyond pagination itself. It frequently highlights broader architectural issues related to internal linking, crawl efficiency, and content organization.
Common Pagination SEO Mistakes
Despite pagination being a standard website feature, it is surprisingly common to encounter technical mistakes that disrupt how search engines interpret paginated structures. These issues often emerge from development shortcuts, outdated SEO advice, or poorly coordinated architecture decisions.
One of the most frequent mistakes involves canonicalizing all pagination pages to the first page of the sequence. While the intention is usually to consolidate signals, this configuration can cause search engines to ignore deeper pages entirely. As a result, content located on those pages may become harder for crawlers to discover.
Another common problem arises when pagination URLs are blocked through robots directives. Preventing search engines from crawling pagination pages can break the discovery pathway for deeper content items. Even if the content itself is indexable, crawlers may struggle to reach it efficiently.
Infinite pagination loops represent another technical error that occasionally appears on poorly configured systems. Some platforms generate pagination numbers indefinitely, creating URLs such as /page/999/ or /page/5000/ even when no additional content exists. Search engines may attempt to crawl these URLs repeatedly, wasting crawl resources.
Duplicate metadata across pagination pages is also widespread. When every page in a sequence uses identical titles and descriptions, search engines receive little context about how the pages differ from each other.
Parameter interactions introduce additional complications. Sorting options, filters, and tracking parameters can produce multiple URLs representing the same pagination page. Without proper canonical signals, these variations may fragment ranking signals across several versions of the same page.
Another subtle but impactful mistake involves neglecting deep pagination pages entirely. Some sites focus heavily on optimizing the first page of category listings while ignoring the structural role of deeper pages. If those pages are poorly linked or inaccessible to crawlers, valuable content further down the sequence may struggle to gain visibility.
Real-World Pagination Case Studies
Pagination challenges often become clearer when examined through real website scenarios. During technical SEO audits, pagination issues rarely appear as isolated problems. Instead, they tend to emerge as part of broader architectural patterns involving crawl efficiency, internal linking, and large-scale content organization.
ecommerce Website Case Study: One common example comes from large ecommerce catalogs. In one audit that I conducted for a retail website with more than 60,000 products, category pages generated extremely deep pagination chains. Some product categories exceeded 120 pagination pages because each page displayed only twelve products. From a usability perspective this seemed manageable, but from a crawl perspective it created a serious discovery bottleneck.
Log file analysis revealed that search engine crawlers repeatedly visited the first few pages of each category while rarely reaching pages beyond the twentieth position. As a result, many product pages located deep in the listing were discovered slowly and indexed inconsistently.
The solution was not to remove pagination but to redesign the architecture. The product catalog was reorganized into additional subcategories, reducing the number of items per category and significantly shortening pagination depth. At the same time, related product modules were introduced to create cross-linking pathways between product pages. Within several months, product discovery improved and index coverage stabilized.
Tech Blog Case Study: Another case involved a tech blog with more than ten years of archived content. The archive relied heavily on pagination, with some category sections extending to more than fifty pages. However, internal links pointing to deeper pages were limited to the standard “next page” navigation.
Search engines crawled the archive pages, but many older articles received little internal authority because they existed far down the pagination chain. The editorial team addressed this by introducing topic hubs and curated collections that linked to older high-value articles. These hubs created additional discovery paths that complemented the existing pagination structure.
Marketplace Case Study: A third scenario involved a marketplace platform with a complex faceted navigation system. Users could filter listings by dozens of attributes, and each filtered view generated its own paginated results. The number of possible URLs expanded into the hundreds of thousands.
Crawl analysis showed that search engine bots spent a large portion of their crawl budget exploring filtered pagination combinations that produced minimal unique content. By refining which filter combinations were allowed to generate indexable pages and consolidating others through canonical signals, the site dramatically reduced crawl waste.
These examples illustrate a consistent theme: pagination itself is rarely the root problem. The real challenge lies in how pagination interacts with other architectural components such as category structures, internal linking systems, and filtering mechanisms.
Pagination Tools for Technical SEO Analysis
Analyzing pagination effectively requires visibility into how search engines crawl and interpret paginated pages. Several technical SEO tools provide insights that help diagnose pagination issues and guide optimization decisions.
Crawling tools are typically the starting point. Applications such as Screaming Frog or Sitebulb simulate how search engine bots explore a website. By running a crawl, SEO teams can identify pagination chains, examine internal linking patterns, and detect parameterized URLs that may generate excessive pagination variations.
These tools also highlight metadata duplication across paginated pages. Because pagination often produces similar templates, crawlers help reveal whether title tags, canonical tags, and meta descriptions are implemented consistently across the sequence.
Search performance data offers another valuable perspective. Google Search Console can reveal how pagination pages appear in search results and whether they are being indexed as expected. If deeper pagination pages unexpectedly rank for primary keywords, it may indicate that the main category page lacks sufficient optimization signals.
Server log analysis provides perhaps the most detailed view of pagination behavior. By analyzing raw server logs, SEO specialists can observe exactly how search engine bots navigate pagination sequences. Patterns often emerge showing which pages are crawled most frequently and how far bots travel through pagination chains.
For large enterprise sites, log analysis frequently reveals crawl inefficiencies that traditional crawlers cannot detect. Bots may repeatedly revisit early pagination pages while rarely reaching deeper sections of the listing.
Technical SEO platforms also help monitor performance signals across paginated pages. Because listing pages often contain numerous images and interactive elements, monitoring Core Web Vitals metrics can reveal whether pagination pages are contributing to performance issues.
DefiniteSEO’s SEO Checker can also assist in identifying technical inconsistencies across pagination pages, particularly related to metadata implementation, canonicalization, and crawl accessibility. When used alongside crawling and log analysis tools, these insights help build a comprehensive picture of how pagination affects a site’s technical health.
Pagination Best Practices Summary
After examining pagination from multiple angles, architecture, crawl behavior, indexing strategy, and user experience, several consistent principles emerge.
First, pagination should always remain crawlable. Search engines rely on pagination links to discover deeper content within listings. Blocking or hiding these links can disrupt discovery pathways and weaken internal linking structures.
Second, each pagination page should typically maintain its own canonical reference. Self-referencing canonical tags help search engines understand that each page represents a distinct segment of the listing while still belonging to a larger sequence.
Third, URL structures should remain clean and predictable. Consistent pagination patterns make it easier for search engines to interpret relationships between pages and reduce the risk of parameter-based duplication.
Fourth, pagination should not operate in isolation. Its effectiveness depends heavily on how it interacts with internal linking systems, category architecture, and filtering mechanisms. Strong supporting links from hubs, related content modules, or curated collections can help distribute authority more evenly across deeper content.
Fifth. Performance considerations also play an important role. Paginated pages often contain large numbers of images and elements, so optimizing loading speed and layout stability is essential for maintaining strong Core Web Vitals metrics.
Future of Pagination in AI Search Ecosystems
Search technology is gradually shifting from simple keyword retrieval toward more sophisticated AI-driven information systems. As generative search experiences expand, the way search engines interpret website structures may continue to evolve.
Pagination could play a subtle but important role in this transformation.
Traditional search engines primarily index individual URLs and evaluate them independently for ranking. AI-driven systems, however, increasingly attempt to understand the broader context in which information appears. Instead of focusing only on single pages, they analyze collections of related content across entire websites.
Paginated series naturally represent structured content collections. A category page followed by multiple pagination pages signals that the site contains a large dataset related to a specific topic or product category.
For example, a paginated archive of tutorials about search engine optimization indicates that the website contains a comprehensive knowledge base on that subject. AI-driven search systems may use this structure to infer topical authority or depth of coverage.
Pagination can also help AI systems identify relationships between entities. Product listings connect multiple related entities within a consistent category framework. Article archives connect pieces of content that belong to the same topic cluster.
As generative search engines continue to evolve, structured navigation systems may become increasingly valuable signals. Pagination provides a simple but powerful mechanism for organizing large information sets in a way that both humans and machines can interpret.
That said, future search systems will likely place even greater emphasis on semantic relationships, entity recognition, and contextual linking. Pagination alone will not establish topical authority, but when combined with strong internal linking and well-organized content hubs, it can contribute to clearer information architecture.
FAQs
What is pagination in SEO?
Pagination in SEO refers to dividing large sets of content or listings into multiple sequential pages so that users and search engines can navigate them efficiently.
Does pagination hurt SEO rankings?
Pagination itself does not harm rankings when implemented correctly, but poor pagination structures can waste crawl budget and weaken internal linking signals.
Should paginated pages be indexed?
In most cases paginated pages should remain indexable because they help search engines discover deeper content within listings.
Is infinite scroll bad for SEO?
Infinite scroll can cause crawlability issues if content is loaded dynamically without crawlable URLs, but hybrid implementations with paginated URLs work well for SEO.
Should pagination pages use canonical tags?
Yes, pagination pages should generally use self-referencing canonical tags so that each page is treated as a unique segment of the listing.
How many pagination pages are too many?
There is no strict limit, but very deep pagination chains can reduce crawl efficiency and may require improved category structures or additional internal links.
Should paginated pages appear in XML sitemaps?
Typically pagination pages are not included in XML sitemaps because sitemaps are better reserved for primary content pages such as product pages or articles.
Does pagination create duplicate content?
Pagination does not automatically create duplicate content, although poorly configured metadata or parameter URLs can cause duplication issues.
What is the best URL structure for pagination?
Clean and consistent URL structures such as /category/page/2/ help search engines clearly understand pagination sequences.
Can pagination affect crawl budget?
Yes, large pagination chains combined with filters or parameters can consume significant crawl budget and should be carefully managed.