Crawl budget optimization ensures search engines efficiently discover, crawl, render, and index your most important pages. It goes beyond counting how many URLs Googlebot visits and focuses on crawl demand, server capacity, internal linking, duplicate control, faceted navigation, and JavaScript rendering. When crawl resources are wasted on low-value or parameterized URLs, indexing slows and priority pages lose visibility. This guide explains how crawl budget works and how to improve crawl efficiency for enterprise, ecommerce, and content-driven websites.
Crawl Budget Optimization – Table of Contents
- What Is Crawl Budget in Modern SEO?
- How Search Engines Allocate Crawl Budget
- Crawl Demand vs Crawl Capacity: The Two Pillars
- Why Crawl Budget Still Matters in 2026 (Despite What Google Says)
- How Googlebot Actually Crawls Websites
- The DefiniteSEO Crawl Budget Optimization Framework
- Identifying Crawl Budget Wastage
- Log File Analysis for Crawl Budget Insights
- Faceted Navigation & Parameter Handling
- Internal Linking and Crawl Depth Engineering
- JavaScript, Rendering & Crawl Delays
- Server Performance & Crawl Rate Limits
- XML Sitemaps and Crawl Signal Optimization
- Managing Large & Enterprise Websites
- Crawl Budget for E-Commerce Sites
- AI Search Engines & Crawl Efficiency in Generative Indexing
- Crawl Budget KPIs & Monitoring Dashboards
- Step-by-Step Crawl Budget Optimization Checklist
- Common Crawl Budget Myths
- Advanced Case Study: Enterprise Crawl Recovery
- FAQs
What Is Crawl Budget in Modern SEO?
Crawl budget is often explained in a single sentence: the number of URLs a search engine bot will crawl on your site within a given timeframe. That definition is technically accurate, but it barely scratches the surface.
In modern SEO, crawl budget is better understood as a resource allocation system. Search engines like Google assign a finite amount of crawling attention to every domain. That attention is influenced by server stability, site structure, content freshness, popularity signals, and historical crawl patterns. When that allocation is spent inefficiently, indexing slows down, updates are missed, and large portions of a site may remain undiscovered.
For smaller websites, crawl budget issues may feel invisible. But as websites grow, especially beyond a few thousand URLs, inefficiencies begin compounding. Parameter variations, filtered pages, soft 404s, redirect chains, duplicate content clusters, and orphaned URLs all start competing for crawl attention. The result is not necessarily deindexation. The more common problem is delayed indexing and poor recrawl frequency for important pages.
Crawl budgett no longer affects only indexing. It influences:
- Rendering priority for JavaScript-heavy pages
- Content freshness evaluation
- AI-driven answer engine ingestion
- Structured data extraction cycles
Modern engines increasingly operate in two stages: crawl and render. When crawl allocation is inefficient, rendering gets delayed. That delay affects how quickly changes are reflected in search results and AI summaries.
At DefiniteSEO, we treat crawl budget as infrastructure SEO. It is not a trick to manipulate Googlebot. It is about building a technically efficient ecosystem where search engines spend their time on pages that matter.
If you have ever updated a key page and wondered why it took weeks to reflect in search results, crawl inefficiency is often the hidden reason.
How Search Engines Allocate Crawl Budget
Search engines do not assign crawl budget randomly. The process is governed by a dynamic balance between demand and capacity.
At a simplified level, there are two main components:
- Crawl demand
- Crawl capacity
But under the hood, allocation is influenced by multiple real-time signals that are continuously recalculated.
Crawl Demand
Crawl demand reflects how important or fresh a page appears to the search engine. Pages that are frequently updated, heavily linked internally, or receive strong external signals tend to be crawled more often.
Demand is shaped by:
- Historical update frequency
- Internal link prominence
- External backlinks
- XML sitemap signals
- User engagement indicators
When a site publishes new content regularly and maintains clean architecture, search engines learn that frequent crawling is worthwhile. On the other hand, if a site rarely changes and contains large volumes of thin or duplicate pages, demand drops.
Demand is not equal across all URLs. A homepage might be crawled multiple times per day, while deep filter pages may be crawled once every few weeks, if at all.
Crawl Capacity
Crawl capacity is based on server health and responsiveness. Search engines test how much they can crawl without overwhelming your infrastructure.
If your server returns errors, responds slowly, or throttles connections, search engines reduce crawl rate automatically. This is a protective mechanism.
Capacity is influenced by:
- Server response time
- Error rate (4xx and 5xx codes)
- Host stability
- CDN performance
- Historical crawl tolerance
Capacity fluctuates. During site migrations or server instability, crawl rate often drops. Once stability improves, allocation may gradually increase again.
Adaptive Crawl Behavior
Search engines continuously adjust crawl rate based on observed behaviorr. If new content is added daily and the server handles traffic well, crawl allocation expands. If thousands of duplicate parameter URLs suddenly appear, crawl demand may spike temporarily, but efficiency drops.
Crawl Demand vs Crawl Capacity: The Two Pillars
To truly optimize crawl budget, you must understand the tension between demand and capacity.
Think of crawl demand as the search engine’s motivation to visit your site, and crawl capacity as its ability to do so safely.
When demand exceeds capacity, the system compensates. Crawl frequency drops or becomes more selective. Important pages may be deprioritized simply because the crawler encounters too many low-value URLs first.
When capacity exceeds demand, the opposite occurs. The search engine has room to crawl more but sees little reason to do so. This often happens on static sites that publish infrequently.
The goal of crawl budget optimization is not to maximize crawl rate. It is to align demand and capacity so that:
- High-value URLs are discovered quickly
- Updated pages are recrawled efficiently
- Low-value URLs do not consume crawl slots
I often audit enterprise sites where millions of URLs exist but only a fraction deserve regular crawling. In such cases, internal linking architecture, canonicalization, parameter control, and sitemap segmentation become strategic tools rather than routine hygiene tasks.
Why Crawl Budget Still Matters in 2026 (Despite What Google Says)
Over the years, representatives from Google and their documentation have repeatedly stated that crawl budget is not a concern for most small to medium-sized websites. That statement is technically true in isolation.
However, the real-world application is more nuanced.
Crawl inefficiencies rarely cause immediate penalties. Instead, they create silent friction:
- New pages take longer to index
- Content updates are reflected slowly
- Thin or low-value pages get crawled repeatedly
- High-priority URLs compete with parameter variations
In audits conducted across SaaS platforms, ecommerce stores, and content publishers, one pattern consistently emerges: sites with poor crawl hygiene suffer from indexing latency.
Even websites under 10,000 URLs can experience crawl waste due to:
- Faceted navigation filters
- Infinite calendar structures
- Session-based parameters
- Auto-generated tag archives
Another overlooked factor is AI ingestion. As AI-driven engines expand, they often crawl aggressively to maintain up-to-date summaries. Crawl efficiency now influences how quickly content appears in generative answers, not just traditional blue links.
So does crawl budget matter in 2026?
Yes, but not as a panic metric. It matters as a performance multiplier. When optimized, it accelerates indexing, strengthens freshness signals, and improves structural clarity.
How Googlebot Actually Crawls Websites
Understanding how Googlebot operates demystifies crawl budget entirely.
Crawling happens in layered stages.

Discovery Layer
First, URLs must be discovered. Discovery happens through:
- Internal links
- XML sitemaps
- External backlinks
- Previously known URLs
If a page is not linked internally and not present in a sitemap, it becomes an orphan. Orphan pages often receive little to no crawl attention.
This is why internal linking architecture is foundational to crawl optimization.
Queue Prioritization
Once discovered, URLs enter a crawl queue. Not all URLs are treated equally.
Search engines use prioritization signals such as:
- Link depth
- Page importance
- Historical crawl frequency
- Update patterns
High-priority URLs are scheduled more frequently. Low-priority ones may wait weeks or months.
This queue-based system explains why publishing large volumes of low-value pages can dilute crawl focus across the entire domain.
Rendering Layer
Modern crawling involves rendering. When JavaScript is required to display meaningful content, the page enters a rendering queue.
Rendering consumes additional resources. It may not happen immediately after crawling. If crawl budget is already stretched thin, rendering delays increase.
For heavily JavaScript-driven websites, crawl budget and render budget become intertwined
A Practical Perspective
In enterprise audits, the biggest crawl inefficiencies rarely come from malicious issues. They come from growth.
New categories are added. Filters expand. Marketing campaigns generate parameterized URLs. Over time, URL sprawl outpaces structural governance.
Search engines respond rationally. They crawl what they see. If what they see is chaotic, crawl allocation becomes inefficient.
The Crawl Budget Optimization Framework (MyMethod)
Crawl budget optimization should never begin with random fixes. Blocking URLs in robots.txt, adding noindex tags, or trimming sitemaps without a structured diagnosis often creates more confusion than clarity. I approach crawl budget as a systems problem. It requires mapping, measurement, consolidation, and infrastructure alignment.
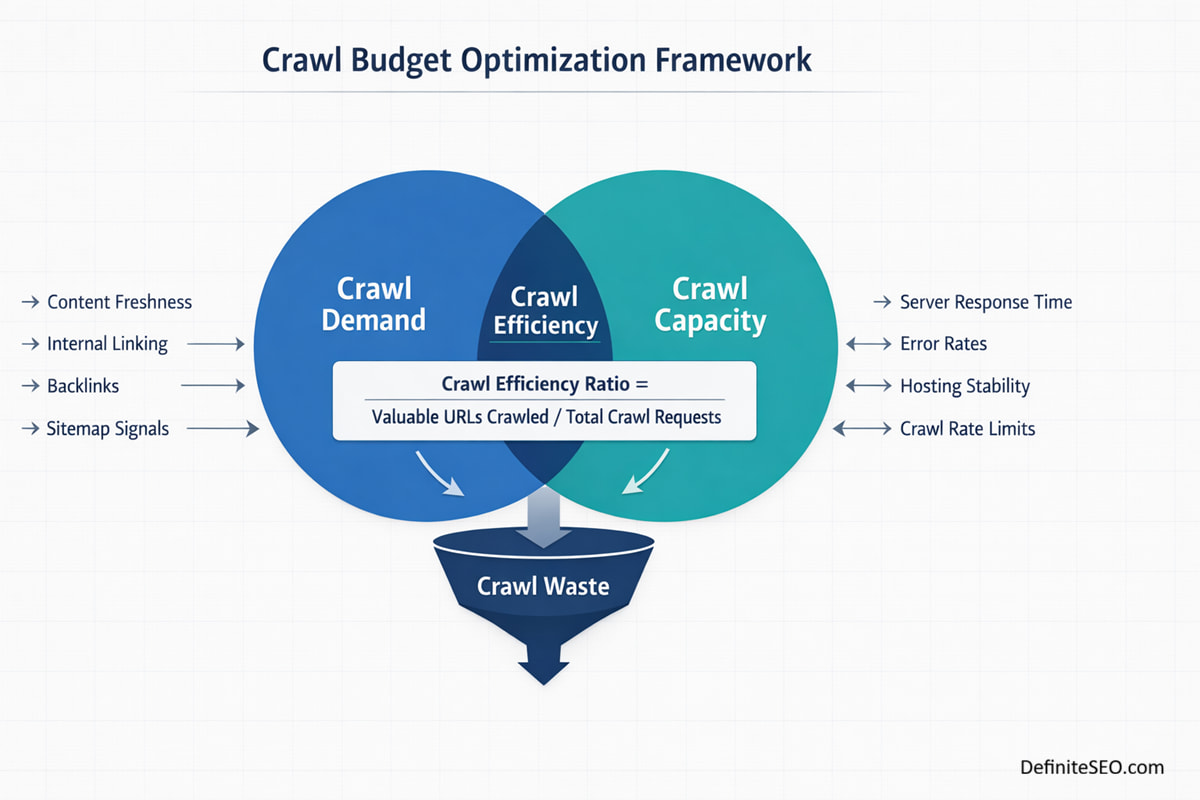
Over years of auditing SaaS platforms, marketplaces, publishers, and large ecommerce brands, I’ve refined a repeatable framework that separates cosmetic SEO fixes from true crawl engineering. The difference is significant. Cosmetic fixes reduce visible clutter. Crawl engineering restructures how search engines interpret and prioritize your entire site.
My method operates in four strategic phases.
Phase 1: Crawl Mapping
The first step is building a complete crawl inventori. This means identifying every discoverable URL across the domain, including parameter variations, pagination sequences, filtered pages, archived taxonomies, and historical legacy URLs.
This is not just about running a crawler. It involves cross-referencing:
- CMS URL generation patterns
- XML sitemap exports
- Server log samples
- Google Search Console coverage data
The goal is to understand the full URL universe. Many enterprise websites believe they have 50,000 URLs when in reality they expose several hundred thousand variations to crawlers.
Mapping also reveals structural imbalances. For example, if 70 percent of discoverable URLs belong to faceted filters while only 10 percent represent revenue-driving pages, crawl inefficiency is already visible at the structural level.
Phase 2: Crawl Waste Identification
Once the URL ecosystem is mapped, the next step is determining where crawl allocation is being wasted. Waste is not simply about broken links. It is about misallocated attention.
Common waste patterns include:
- Duplicate content clusters
- Soft 404 responses
- Redirect chains
- Expired campaign URLs
- Infinite parameter combinations
The key question we ask during audits is simple: If Googlebot spends 1,000 crawl requests on this site today, how many of those requests lead to valuable, index-worthy pages?
The percentage difference between total crawl requests and meaningful crawl destinations is what we refer to internally as crawl efficiency ratio.
Phase 3: Crawl Signal Consolidation
After waste is identified, consolidation begins. This is where canonicalization, internal linking adjustments, parameter handling, and sitemap segmentation are applied strategically rather than mechanically.
Instead of blindly noindexing large sections, the focus shifts to:
- Consolidating duplicate signals under canonical URLs
- Strengthening internal links toward priority pages
- Reducing crawl entry points to low-value areas
- Aligning sitemaps with index-worthy assets only
This phase is surgical. Overblocking can suppress discoverability. Underblocking leaves inefficiencies intact.
Phase 4: Infrastructure & Performance Alignment
Crawl budget does not exist independently of performance. Server responsiveness directly influences crawl capacity. If a host struggles under load, search engines will slow their crawl rate to protect stability.
This is where coordination with developers becomes essential. Improvements may include:
- Reducing server response time
- Optimizing database queries
- Implementing intelligent caching
- Leveraging CDN architecture
The framework is iterative. Crawl optimization is not a one-time cleanup. As websites grow, governance processes must ensure that new URL generation does not reintroduce crawl waste.
Identifying Crawl Budget Wastage
Crawl waste often hides in plain sight. It is embedded in CMS behaviors, filter logic, outdated redirects, and legacy architecture decisions that were never revisited.
The most damaging type of waste is duplication at scale. When similar URLs compete for crawl attention, search engines must evaluate each variation to determine canonical relevance. That evaluation consumes crawl resources, even if only one version is indexed.
Faceted navigation is a frequent offender. Sorting options such as price, color, size, and rating can generate thousands of permutations. Without controlled canonicalization or crawl management, these permutations multiply rapidly.
Another overlooked source of waste is redirect layering. During migrations or redesigns, redirect chains accumulate. A single URL may pass through two or three hops before resolving. Each hop consumez crawl allocation and reduces efficiency.
Soft 404 pages are equally problematic. Pages that technically return a 200 status but provide thin or empty content signal ambiguity. Search engines must re-evaluate them repeatedly before deciding their value.
In most of my audits, one recurring pattern stands out. Many organizations invest heavily in content production but ignore URL lifecycle management. Campaign pages, seasonal categories, discontinued products, and temporary landing pages remain accessible long after they lose relevance. Over time, these accumulate into a crawl drain.
Log File Analysis for Crawl Budget Insights
If crawl budget optimization had a single source of truth, it would be server logs.
Tools like Google Search Console provide aggregated crawl statistics. However, only log files reveal actual bot behavior at the URL level. They show exactly which pages were requested, how often, and what status codes were returned.
By analyzing logs, you can answer critical questions:
- Are important pages being crawled regularly?
- Are parameter URLs consuming disproportionate crawl share?
- Is Googlebot revisiting low-value URLs excessively?
- Are 404 or 301 responses dominating crawl activity?
Log analysis also uncovers bot segmentation. Desktop and mobile user agents may behave differently. Crawl spikes around certain directories can signal structural issues.
For enterprise sites, logs often reveal that only a small subset of high-priority URLs receives consistent crawl frequency, while deep product or blog pages are revisited infrequently. This imbalance directly affects freshness signals and indexing speed.
Effective log analysis involves pattern recognition. Instead of reviewing individual URLs, we categorize by:
- URL type
- Directory
- Parameter presence
- Status code
- Response time
From there, we calculate crawl waste percentage and crawl-to-index ratio.
Faceted Navigation & Parameter Handling
Faceted navigation is one of the most complex crawl budget challenges in modern SEO. It is also one of the most misunderstood.
Ecommerce platforms, marketplaces, and large content repositories rely on filters to improve user experience. However, each filter combination can generate a unique URL. Multiply five filter dimensions across dozens of categories and the URL count expands exponentially.
Without governance, this creates a crawl explosion.
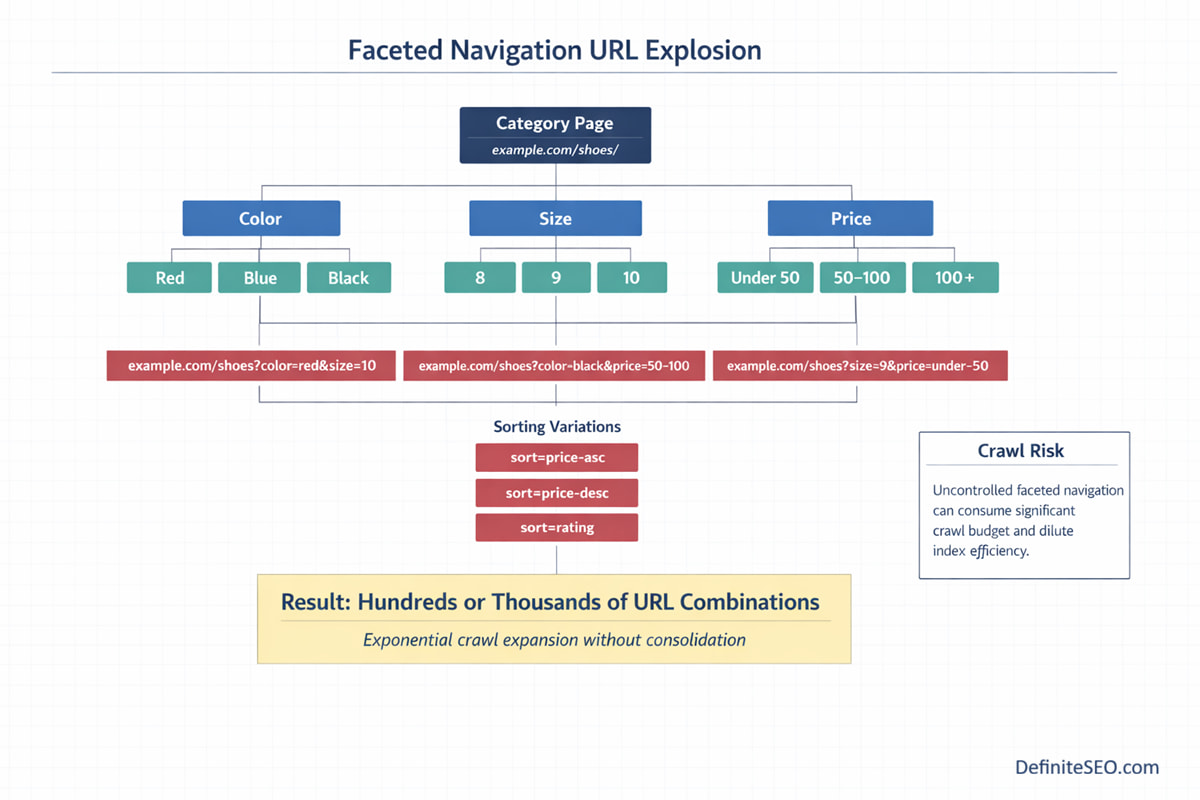
The first step is distinguishing between index-worthy filtered pages and navigational filters. Some filtered combinations represent genuine search demand. Others exist solely for user sorting convenience.
Parameter handling strategies vary depending on intent:
- Canonicalizing filtered pages to primary categories
- Applying noindex to low-value combinations
- Blocking infinite or system-generated parameters
- Consolidating sorting parameters under canonical versions
Overblocking can suppress legitimate long-tail ranking opportunities. Underblocking allows crawl waste to spiral. The balance depends on data.
I often advise clients to map faceted URLs by organic traffic and conversion potential before applying blanket directives. Data-driven prioritization prevents accidental deindexation of high-performing filter pages.
Internal Linking and Crawl Depth Engineering
Internal linking is the most underestimated lever in crawl budget optimization.
Search engines use internal links to determine discovery pathways and importance signals. Pages buried five or six clicks deep inherently receive lower crawl priority unless reinforced through contextual linking.
Crawl depth engineering focuses on reducing unnecessary click distance between important URLs and the homepage or major category hubs.
There are two common architectural patterns:
- Flat architecture, where most important pages are reachable within three clicks
- Deep architecture, where content is layered through multiple subcategories
Flat architecture generally supports faster crawl distribution, but depth can still perform efficiently if internal linking is intellogently structured.
The real issue arises when internal links are inconsistent. For example, if blog posts link randomly without thematic clustering, search engines struggle to interpret hierarchy. This diffuses crawl signals across the site.
Strategic internal linking strengthens crawl demand for priority pages. It also reduces orphan risks and improves index coverage.
I treat internal links as crawl pathways. Every link represents a vote for recrawl frequency. When these votes are aligned with business priorities, crawl allocation becomes intentional rather than incidental.
JavaScript, Rendering & Crawl Delays
Modern websites increasingly rely on JavaScript frameworks to deliver dynamic experiences. From React-based ecommerce platforms to headless CMS deployments, content is often assembled in the browser rather than served as fully rendered HTML. This architectural shift has introduced a second constraint alongside crawl budget: render budget.
When Googlebot encounters a JavaScript-heavy page, the process typically unfolds in two waves. The first wave retrieves the raw HTML. The second wave renders the page to execute JavaScript and extract meaningful content. That second stage is resource-intensive and often delayed.
If crawl budget is inefficient, rendering queues become congested. Pages may be crawled but not rendered promptly. From a reporting perspective, this creates confusion. URLs appear discovered yet remain unindexed for extended periods.
Rendering delays are especially common in:
- Client-side rendered applications
- Infinite scroll implementations
- Lazy-loaded content without proper fallback
- Pages relying on API calls for primary content
The real issue is not JavaScript itself. It is dependency. If essential content, internal links, or canonical signals exist only after JavaScript execution, search engines must expend additional resources to interpret them.
I frequently see crawl delays resolved not by blocking URLs but by improving render efficiency. Server-side rendering, hybrid rendering, and static pre-rendering often reduce crawl latency significantly. Even subtle improvements such as reducing unused JavaScript bundles or optimizing hydration logic can accelerate recrawl cycles.
Server Performance & Crawl Rate Limits
Crawl capacity is directly tied to infrastructure stability. Search engines continuously evaluate how your server responds under load. If response times increase or error rates spike, crawl rate is automatically reduced to protect both the crawler and your host.
This adaptive throttling is often misunderstood. Website owners may assume indexing issues stem from content quality when the underlying problem is technical capacity.
Several server-level factors influence crawl rate:
- Time to first byte
- Frequency of 5xx errors
- Connection timeouts
- Resource bottlenecks during traffic spikes
- Inconsistent CDN behavior
A slow server does not just degrade user experience. It signals to search engines that aggressive crawling could cause instability. As a result, crawl allocation contracts.
I’ve observed cases where improving server response time by a few hundred milliseconds significantly increased crawl frequency across deep directories. The correlation is measurable. Stable infrastructure encourages higher crawl throughput.
There is also a strategic dimension to rate management. Temporary 503 status codes can be used during maintenance windows to prevent indexing disruptions. However, misconfigured responses can suppress crawling for extended periods.
CDN configuration plays a subtle yet important role. When static assets are cached effectively and edge servers respond efficiently, overall crawl capacity increases. Conversely, misaligned caching rules can create inconsistent signals that reduce crawl trust.
XML Sitemaps and Crawl Signal Optimization
XML sitemaps are often treated as submission tools. In reality, they function as crawl prioritization hints.
An optimized sitemap ecosystem does not attempt to list every discoverable URL. Instead, it highlights index-worthy pages and reinforces freshness signals. When sitemaps contain low-value or duplicate URLs, they dilute their own authority.
Search engines use sitemap data to:
- Discover newly published pages
- Understand last modification patterns
- Prioritize recrawl cycles
- Cross-validate canonical signals
The “lastmod” attribute becomes particularly valuable when used accurately. If timestamps are manipulated artificially or updated without meaningful changes, trust declines. Over time, search engines rely less on sitemap freshness hints.
Segmentation is another under utilized tactic. Large sites benefit from dividing sitemaps by content type, category, or update frequency. For example, separating blog posts from product pages allows crawlers to recognize different update rhythms.
Sitemaps also act as diagnostic tools. When URLs appear in sitemaps but remain unindexed, it signals deeper crawl or quality issues. Conversely, if large numbers of indexed pages are absent from sitemaps, structural governance may be lacking.
Managing Large & Enterprise Websites
Crawl budget becomes exponentially more complex at enterprise scale. Once URL counts reach hundreds of thousands or millions, inefficiencies compound rapidly.
Large websites face unique challenges:
- Product catalog expansion
- International subdirectories
- Pagination layers
- Dynamic filters
- Legacy URLs from previous migrations
At this scale, crawl budget optimization shifts from tactical fixes to governance frameworks. It requires ongoing monitoring rather than periodic audits.
One effective approach is URL tiering. Not all pages deserve equal crawl frequency. Revenue-driving categories, high-performing landing pages, and recently updated content should receive priority. Archived, low-traffic, or discontinued pages may require consolidation or de-prioritization.
International sites add another layer. Hreflang clusters multiply URL counts across regions. If canonicalization and language targeting are inconsistent, search engines may repeatedly crawl alternate versions without clear consolidation signals.
Enterprise SEO teams often underestimate the impact of automated CMS features. Bulk-generated tag pages, search result pages, and promotional landing pages can inflate crawl volume dramatically.
Crawl Budget for E-Commerce Sites
Ecommerce websites represent the most fragile crawl ecosystems in SEO. They combine high URL volume with constant change.
Every product variant, filter combination, review page, and sorting parameter creates potential crawl expansion. Meanwhile, inventory fluctuations generate new URLs and retire old ones continuously.
A few recurring crawl challenges in ecommerce environments include:
- Out-of-stock product handling
- Seasonal category transitions
- Faceted filter proliferation
- Pagination across large product sets
Out-of-stock products present strategic decisions. Immediate removal can generate 404 spikes and disrupt internal linking. Retaining them without clear messaging can dilute crawl allocation. The correct approach depends on restock probability and historical performance.
Paginations also influences crawl distribution. If internal links emphasize only the first page of a category, deeper products may receive minimal crawl frequency. Thoughtful linking and structured pagination help distribute crawl demand evenly.
One overlooked factor is user-generated content. Reviews and Q&A sections frequently update product pages. These updates can increase crawl demand organically. However, if rendering is inefficient, those freshness signals may not be recognized promptly.
Ecommerce crawl optimization ultimately revolves around prioritization. High-margin products, top categories, and conversion-focused pages should receive the strongest crawl signals. Structural noise must be contained.
AI Search Engines & Crawl Efficiency in Generative Indexing
Crawl budget is no longer a conversation limited to traditional search engines. As AI-driven answer engines mature, crawl efficiency directly influences how quickly and accurately your content is interpreted, summarized, and surfaced in generative responses.
Platforms such as ChatGPT, Perplexity AI, and Google Gemini increasingly rely on structured crawling, retrieval systems, and refreshed indexing pipelines to provide up-to-date answers. While their underlying architectures differ from traditional search engines, the dependency on accessible, crawlable content remains foundational.
Generative systems introduce a new layer: content extraction for summarization. When AI systems crawl websites, they are not only determining index eligibility. They are evaluating entity relationships, structured data, topical completeness, and contextual clarity.
If crawl efficiency is compromised, two issues arise:
- Updated content may not be ingested promptly
- Entity relationships may be misinterpreted or underweighted
In AI search environments, freshness cycles are becoming shorter. Engines are attempting to deliver real-time or near-real-time insights. A website that restricts or misdirects crawl paths risks delayed inclusion in generative answers.
Structured data plays a complementary role. When schema markup is implemented correctly, AI systems can interpret product details, FAQs, organizational data, and article metadata with greater confidence. Crawl clarity enhances generative accuracy.
Crawl Budget KPIs & Monitoring Dashboards
Optimization without measurement is guesswork. Crawl budget performance should be monitored with clearly defined KPIs that reflect both efficiency and impact.
Traditional metrics such as total crawl requests provide limited insight. What matters is quality of crawl distribution.
Key performance indicators typically include:
- Crawl-to-index ratio
- Percentage of crawl requests returning non-200 status codes
- Crawl frequency of high-priority URLs
- Crawl waste percentage across parameterized URLs
- Average response time for bot requests
A strong crawl-to-index ratio indicates that most crawled URLs are worthy of indexing. A low ratio often signals duplication, thin content, or structural noise.
Log files remain the most reliable data source for accurate crawl metrics. However, dashboards can combine log insights with Search Console data and analytics to create a holistic view.
Dashboards should segment URLs by type. Blog posts, product pages, categories, filters, and legacy directories should be evaluated independently. Aggregatee metrics often conceal imbalance.
Step-by-Step Crawl Budget Optimization Checklist
Crawl budget optimization is best approached as a structured workflow rather than isolated fixes. While each site has unique complexities, the core execution sequence remains consistent.
Step 1: The process begins with comprehensive crawling and URL mapping. Every discoverable URL must be categorized by type, value, and intent. Without this foundational inventory, optimization becomes speculative.
Step 2: Next comes crawl behavior validation. Log file analysis confirms whether high-value pages are receiving sufficient attention. This stage frequently uncovers disproportionate crawl activity concentrated on filters, parameters, or deprecated directories.
Step 3: Once inefficiencies are identified, consolidation measures are implemented. Canonical tags are aligned, internal links are restructured, and redundant URL pathways are reduced. Sitemaps are refined to include only index-worthy pages.
Step 4: Infrastructure optimization follows. Server response times are improved, error rates are addressed, and caching logic is reviewed. Stability ensures that crawl capacity is not artificially constrained.
Step 5: Finally, monitoring and governance processes are formalized. New site features, marketing campaigns, or CMS changes should include crawl impact assessments. Without long-term governance, crawl inefficiencies inevitably resurface.
Common Crawl Budget Myths
Crawl budget discussions are often clouded by oversimplification. Misconceptions lead to unnecessary blocking strategies and missed opportunities.
One persistent myth suggests that crawl budget only matters for very large websites. In reality, inefficiency can affect small and mid-sized sites when parameter sprawl or duplication exists. Crawl budget is about proportional waste, not absolute size.
Another misconception is that blocking URLs in robots.txt automatically saves crawl budget. While blocking can prevent crawling of specific paths, it does not eliminate discoverability signals entirely. If blocked URLs remain linked internally, search engines still allocate evaluation effort.
There is also a belief that Google eventually crawls everything. In practice, low-priority URLs may remain infrequently crawled for extended periods, especially when demand signals are weak.
Some assume that sitemap priority values directly control crawl frequency. Search engines treat priority hints as secondary signals at best. Structural clarity and internal linking carry more weight.
Perhaps the most damaging myth is that more indexed pages equal better performance. Index bloat often dilutes topical authority and crawl focus. Quality and prioritization outperform volume.
Advanced Case Study: Enterprise Crawl Recovery
To illustrate how crawl budget optimization translates into measurable impact, consider an anonymized enterprise ecommerce platform with over two million discoverable URLs.
The organization experienced slow indexing of new products, inconsistent category visibility, and rising index coverage warnings. Initial diagnostics suggested content quality issues. However, log file analysis revealed a different narrative.
Nearly 40 percent of crawl requests were directed toward parameterized filter URLs. An additional 18 percent were consumed by legacy campaign pages returning redirect chains. High-value product pages beyond the third pagination layer received minimal crawl frequency.
The recovery process followed my above framework.
First, URL mapping exposed over 800,000 low-value filter combinations. Canonicalization rules were refined, and certain parameters were consolidated under primary category URLs. Internal linking was adjusted to strengthen deep product discovery.
Second, redirect chains were flattened. Historical campaign URLs were either consolidated or retired with clean status handling.
Third, sitemap segmentation prioritized active products and high-margin categories. Legacy URLs were removed from index-oriented sitemaps.
Fourth, server response times were optimized through improved caching and CDN adjustments.
Within three monthsz, measurable improvements emerged. Crawl waste percentage declined significantly. Crawl frequency of revenue-driving categories increased. Indexation of new products accelerated. Organic revenue grew in correlation with improved crawl distribution.
The lesson was clear. The site did not suffer from insufficient crawl budget. It suffered from misdirected crawl allocation.
FAQs on Crawl Budget Optimization
How do I know if my website has a crawl budget problem?
If important pages are indexed slowly, updated content takes weeks to reflect, or log files show bots spending excessive time on low-value URLs, you likely have crawl inefficiencies.
How many URLs are too many for Google to crawl?
There is no fixed limit; crawl issues arise when low-value or duplicate URLs consume a disproportionate share of crawl resources.
Does blocking URLs in robots.txt save crawl budget?
Blocking can reduce crawl access, but if URLs remain discoverable through internal links, they may still consume evaluation resources.
Should I noindex faceted navigation pages?
Only if they do not serve search intent or conversion value; high-performing filter pages may deserve indexing with proper canonical control.
How often does Google adjust crawl rate?
Crawl rate adapts dynamically based on server performance, update frequency, and historical demand signals.
Can slow hosting reduce my crawl budget?
Yes, unstable or slow servers trigger automatic crawl throttling to prevent overload.
Is crawl budget different for mobile-first indexing?
Mobile-first indexing uses mobile user agents for crawling, but overall crawl allocation principles remain the same.
Do AI search engines use crawl budgets?
AI-driven engines also operate within resource constraints and prioritize efficiently crawlable, well-structured content for generative indexing.