Redirects are one of the most critical yet misunderstood components of Technical SEO. Whether you are migrating a website, fixing broken URLs, or consolidating duplicate content, the way redirects are implemented directly impacts crawlability, indexation, and ranking signals. This guide breaks down everything you need to know about SEO redirects, from how search engines interpret them to how to implement them correctly for maximum performance and long-term scalability.
Overview
- What are Redirects in Technical SEO
- How Search Engines Process Redirects
- Complete Guide to HTTP Status Codes for Redirects
- Types of Redirect Implementations (Technical)
- When to Use Redirects
- Redirects and Link Equity: What Actually Transfers
- Redirect Chains and Loops: Diagnosis & Fixes
- Redirects and Crawl Budget Optimization
- Redirect Mapping for SEO Migrations
- Redirects vs Canonical Tags vs Noindex: When to Use What
- Redirects in JavaScript SEO & Rendering Environments
- International SEO & Redirects
- Mobile SEO and Redirects
- Redirects and Site Architecture
- Performance Impact of Redirects
- Common Redirect Mistakes That Kill SEO Performance
- Redirect Auditing: Step-by-Step Process
- Practical Implementation Examples
- FAQs
1. What are Redirects in Technical SEO
Redirects sit quietly in the background of the web, yet they influence nearly every core SEO signal, from how pages are discovered to how authority flows across a site. At a surface level, a redirect simply sends users and bots from one URL to another. At a protocol level, though, it is a structured HTTP response where the server communicates a status code along with a new destination. The browser receives this response, automatically requests the new URL, and continues rendering the page. This exchange happens in milliseconds, but for search engines, it carries layered meaning about intent, permanence, and relevance.
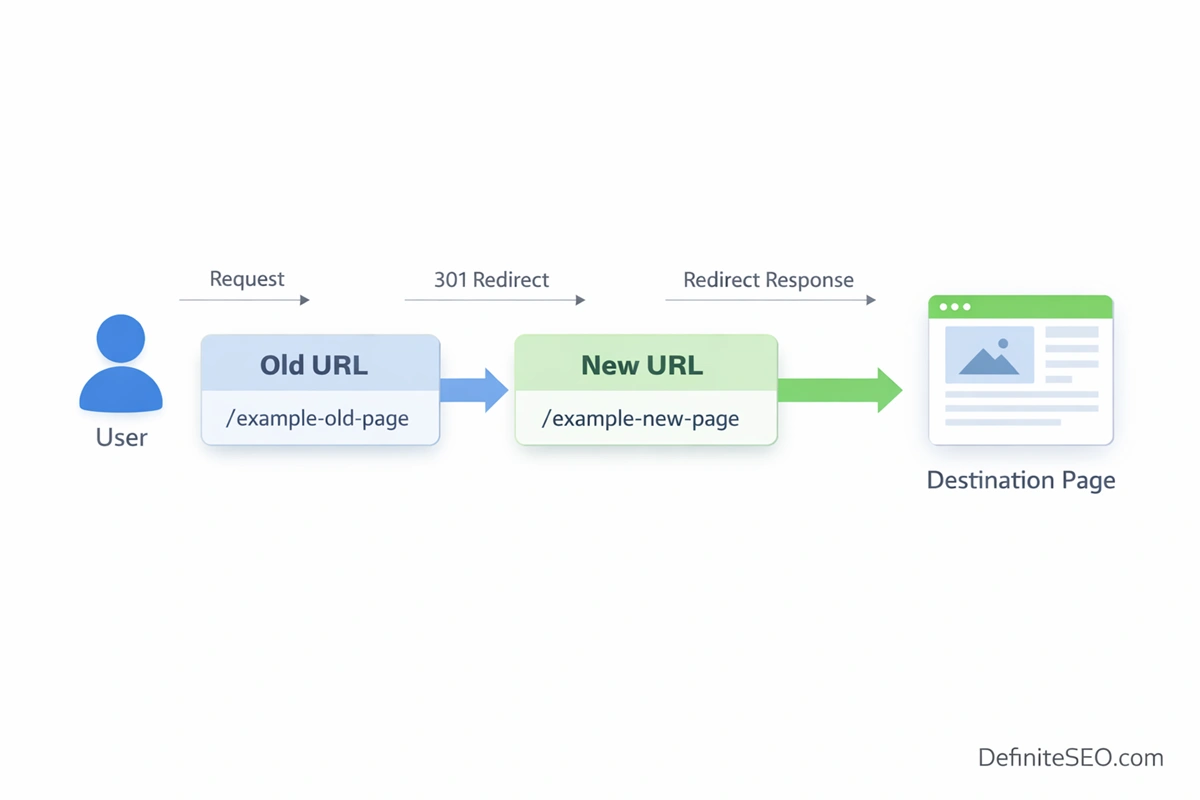
From a technical perspective, redirects are instructions embedded in the HTTP communication cycle. When a request is made to a URL, the server can either return content or signal that the content has moved. That signal is expressed through status codes like 301 or 302, which guide both browsers and crawlers. Modern browsers follow redirects seamlessly, often without the user noticing. Search engines, however, do not simply follow them. They interpret them.
2. How Search Engines Process Redirects
Search engines do not treat redirects as simple instructions to “go somewhere else.” Each redirect is evaluated through a sequence of systems that determine how it affects crawling, indexing, and ranking signals. While the underlying process is complex, it can be understood in four core stages that reflect how modern search engines actually operate.
Search engines rely on multiple discovery and consolidation signals working together, not in isolation. Alongside redirects, a properly structured XML sitemap helps crawlers quickly identify final destination URLs, ensuring that redirected pages are discovered, processed, and indexed more efficiently.
2.1 Crawl Request and Redirect Discovery
The process begins when a crawler requests a URL. If the server responds with a redirect status code instead of a standard page, the crawler immediately recognizes that the content has moved.
At this point, the search engine records the type of redirect and the destination URL. This initial signal is critical because it frames how the redirect will be interpreted later. A permanent redirect suggests replacement, while a temporary one suggests continuity of the original URL.
If multiple redirects exist, the crawler follows each step until it reaches a final destination. The entire path is evaluated, not just the endpoint, which is why long chains introduce inefficiencies.
2.2 Rendering and Redirect Interpretation
Not all redirects are discovered at the server level. In modern websites, some redirects are triggered through JavaScript, which means they are only visible after rendering.
Search engines like Google process pages in two layers: crawling first, rendering second. If a redirect is embedded in JavaScript, it may not be detected immediately. Instead, it waits in the rendering queue, which can delay how quickly the redirect is processed.
This is one reason server-side redirects remain more reliable. They are discovered instantly, while client-side redirects depend on additional processing resources.
2.3 Indexing Decisions and URL Selection
Once the crawler reaches the final destination, the search engine decides which URL should be indexed. This is where redirect intent is evaluated more deeply.
Permanent redirects usually result in the destination URL replacing the original in the index. Temporary redirects may keep the original URL indexed, but this depends on how the redirect behaves over time.
Search engines are no longer rigid in their interpretation. If a temporary redirect persists long enough, it may be treated as permanent. Similarly, inconsistent redirects can create ambiguity, delaying indexing decisions.
2.4 Signal Consolidation and Crawl Efficiency
After indexing decisions are made, search engines begin consolidating signals. This includes transferring link equity, anchor relevance, and historical data from the original URL to the destination.
At the same time, efficiency is evaluated. Each redirect requires an additional request, which affects crawl budget. On large sites, excessive redirects or long chains can limit how many pages are crawled and updated.
3. Complete Guide to HTTP Status Codes for Redirects
Redirects are defined by HTTP status codes, and each code communicates a specific intent to both browsers and search engines. While the differences may seem subtle, they can lead to very different SEO outcomes.
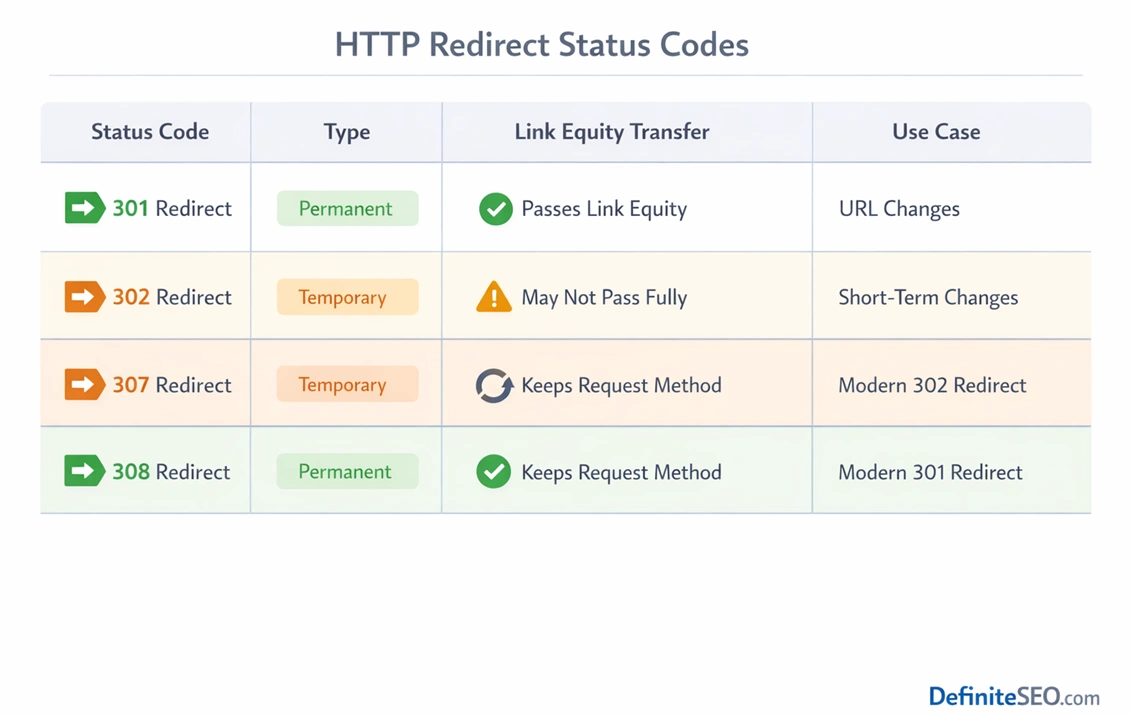
301 (Permanent Redirect) – The Standard
The 301 redirect is the most widely used and trusted method for indicating that a URL has permanently moved. When implemented correctly, it signals that all future requests should be directed to the new URL. Search engines treat this as a strong canonical signal, often replacing the old URL in their index with the new one.
From an SEO standpoint, a 301 redirect passes the majority of link equity from the original page to the destination. Modern search engines have largely eliminated the historical loss associated with redirects, but that does not mean implementation quality can be ignored. Relevance still matters. If the destination page does not closely match the original intent, the transfer of value may be diluted.
Misuse of 301 redirects is more common than expected. Redirecting multiple unrelated pages to a single destination, such as a homepage, is a typical mistake. Another issue arises during migrations when redirects are implemented without updating internal links, creating unnecessary dependency on redirect chains.
302 (Temporary Redirect) – Misunderstood Signal
The 302 redirect was originally designed to indicate a temporary move. In theory, search engines should continue indexing the original URL while temporarily sending users to another location. In practice, things are more nuanced.
Modern search engines evaluate how long a 302 remains in place. If it persists, they may begin treating it as a permanent redirect. This behavior reflects a shift toward interpreting real-world usage rather than strictly following protocol definitions.
There are valid use cases for 302 redirects. These include A/B testing, temporary promotions, and maintenance scenarios where the original URL is expected to return. Problems arise when 302 redirects are used unintentionally during migrations or structural changes. In such cases, search engines may struggle to determine the correct canonical URL, leading to indexing inconsistencies.
307 & 308 Redirects – Modern Alternatives
The 307 and 308 status codes were introduced to address ambiguities in earlier redirect definitions. A 307 redirect functions as a temporary redirect, similar to 302, but preserves the original request method. A 308 redirect is the permanent counterpart, offering a clearer alternative to 301 in certain technical scenarios. For a deeper technical understanding, the official RFC specification (https://datatracker.ietf.org/doc/html/rfc7538) defines how modern redirect status codes like 308 are intended to function at the protocol level, including method preservation and caching behavior.
While these codes are more precise from a protocol standpoint, their SEO impact is largely aligned with their traditional counterparts. A 308 is treated similarly to a 301 in most cases. The choice between them often depends on technical requirements rather than SEO considerations.
In environments where request methods must remain unchanged, such as APIs or form submissions, these codes offer greater control. For typical website migrations, however, 301 remains the default choice due to its widespread adoption and compatibility.
Understanding how different status codes behave is critical for correct implementation. The complete breakdown of HTTP response codes and their behavior is well documented at https://developer.mozilla.org/en-US/docs/Web/HTTP/Status, which serves as a reliable reference for both developers and SEO professionals.
Meta Refresh Redirects
Meta refresh redirects occur at the page level rather than the server level. They are implemented using HTML and instruct the browser to refresh the page after a specified delay, often redirecting to a new URL.
From an SEO perspective, these redirects are weaker signals. They rely on the browser rather than the server, which introduces ambiguity for search engines. While Google can process them, they are not recommended for standard use.
There are limited scenarios where meta refresh redirects may be acceptable, such as user-facing notifications where a delay is intentional. Even in those cases, they should be used cautiously and not as a replacement for proper server-side redirects.
JavaScript Redirects
JavaScript redirects have become more common with the rise of modern web frameworks. These redirects are executed on the client side and require the page to be rendered before the redirect is triggered.
Search engines like Google can process JavaScript redirects during the rendering phase, but this introduces complexity. Rendering is resource-intensive and may not happen immediately. This delay can affect how quickly redirects are discovered and processed.
In client-side rendering environments, improper use of JavaScript redirects can lead to indexing issues, especially if the redirect is not consistently executed. For this reason, server-side redirects remain the preferred approach whenever possible. JavaScript redirects should be reserved for cases where server-level control is not feasible.
4. Types of Redirect Implementations (Technical)
Redirects can be implemented at multiple layers of a website’s infrastructure, and each layer comes with its own trade-offs in terms of performance, flexibility, and SEO reliability.
4.1 Server-Level Redirects
Server-level redirects are the most direct and efficient form of implementation. They occur before any page content is loaded, making them both fast and reliable. Configurations can be handled through Apache’s .htaccess files, Nginx rules, or IIS settings, depending on the server environment.
Because these redirects operate at the earliest stage of the request cycle, they minimize latency and ensure that both users and crawlers are immediately directed to the correct URL. This makes them the preferred choice for most SEO-critical scenarios, including migrations and canonicalization.
4.2 Application-Level Redirects
Application-level redirects are handled within the CMS or backend logic of a website. Platforms like WordPress, Shopify, and headless CMS solutions often provide built-in tools or plugins for managing redirects.
While these are easier to implement, they are generally less efficient than server-level redirects. The request must pass through the application layer before the redirect is triggered, which can introduce additional processing time.
That said, application-level redirects offer flexibility, especially for non-technical teams. They are useful for managing individual URL changes or smaller-scale updates without requiring server access.
4.3 Edge & CDN Redirects
Edge-level redirects are executed at the CDN level, closer to the user’s geographic location. Services like Cloudflare, Akamai, and Fastly allow redirects to be configured at the network edge, reducing latency and improving performance.
From an SEO standpoint, edge redirects combine speed with scalability. They are particularly valuable for global websites where reducing response time across regions is critical. They also allow for advanced routing logic without placing additional load on the origin server.
4.4 Client-Side Redirects
Client-side redirects rely on the browser to execute logic after the page has loaded. These are typically implemented using JavaScript and are common in single-page applications.
While they offer flexibility, they come with SEO risks. Because they depend on rendering, there is a delay before the redirect is executed. This can lead to inconsistent crawling and indexing, especially if search engines do not fully render the page.
In most cases, client-side redirects should be treated as a fallback rather than a primary solution.
5. When to Use Redirects
Redirects are not just technical tools. They are strategic decisions that shape how authority, relevance, and user experience are preserved over time.
5.1 URL Changes and Content Migration
When URLs change due to restructuring, rebranding, or optimization, redirects ensure continuity. Without them, search engines treat the new URL as a completely separate entity, resulting in lost rankings and broken links. A well-planned redirect preserves both user access and accumulated authority.
5.2 Domain Migration
Domain migrations are among the most sensitive SEO operations. Redirects play a central role in transferring authority from the old domain to the new one. Every important URL must be mapped accurately to its new counterpart. Even minor gaps in this mapping can lead to significant traffic loss.
5.3 HTTP to HTTPS Migration
Moving from HTTP to HTTPS is now standard practice, not just for security but also for trust and ranking signals. Redirects ensure that all traffic is consistently directed to the secure version of the site. This transition must be handled carefully to avoid duplicate content issues and signal fragmentation.
5.4 Handling Deleted or Expired Content
Not all removed content should be redirected. The decision between a redirect, a 404, or a 410 depends on context. If there is a relevant replacement, a redirect is appropriate. If the content is permanently gone with no equivalent, a 410 may be the cleaner signal. Misusing redirects in these cases can confuse search engines and dilute topical relevance.
5.5 Canonicalization & Duplicate Control
Redirects are one of the strongest tools for resolving duplicate content issues. Unlike canonical tags, which are hints, redirects enforce a single version of a URL. This makes them particularly effective for consolidating signals across variations such as trailing slashes, uppercase URLs, or parameterized pages.
5.6 Merging Content for Authority Consolidation
Content consolidation is often overlooked as a use case for redirects. When multiple weaker pages are combined into a stronger, more comprehensive resource, redirects ensure that existing signals are not lost. This approach aligns with modern SEO strategies that prioritize depth and authority over fragmented content.
From experience at DefiniteSEO, this is one of the most impactful uses of redirects. When executed correctly, consolidating overlapping content can lead to noticeable improvements in rankings, not because new content was added, but because existing authority was unified under a single, stronger page.
6. Redirects and Link Equity: What Actually Transfers
When SEOs talk about redirects, the conversation often circles back to one question: how much value actually passes through them? The answer is more nuanced than the old “link juice loss” narrative that still lingers in many discussions.
At its core, link equity, often associated with PageRank, flows through redirects as part of how search engines consolidate signals. When a page is redirected using a permanent method such as a 301, search engines treat the destination as the successor of the original URL. This means that backlinks, authority signals, and historical relevance are transferred to the new location. Over time, the original URL is typically replaced in the index.
The idea that redirects inherently cause significant loss of link equity is largely outdated. Modern search engines have refined how they process redirects, and in most standard cases, the transfer is close to complete. However, “close to complete” does not mean identical. Context still matters. If the destination page is not relevant to the original, the transfer may be weakened. Search engines evaluate semantic alignment, not just the presence of a redirect.
Where issues begin to surface is in multi-hop scenarios. A single redirect from A to B is usually handled efficiently. But when A redirects to B, which redirects to C, and sometimes even further, each additional step introduces friction. While search engines can follow these chains, signal consolidation becomes less efficient. There is also a higher chance of partial signal loss or delayed consolidation, especially if the chain changes over time.
7. Redirect Chains and Loops: Diagnosis & Fixes
Redirect chains and loops are among the most common technical SEO issues found during audits. They often emerge gradually, especially on sites that have undergone multiple updates, migrations, or CMS changes over time.
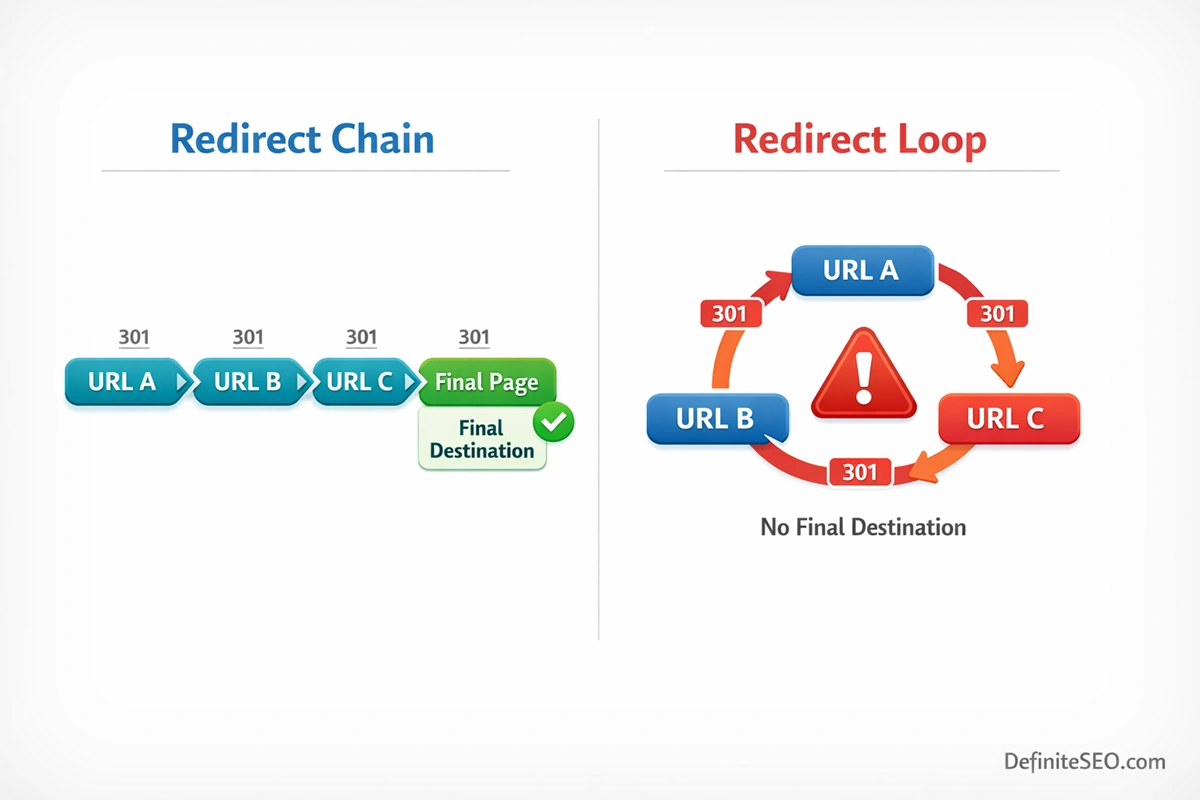
7.1 What Are Redirect Chains
A redirect chain occurs when one URL redirects to another, which then redirects again, creating a sequence rather than a direct path. For users, this introduces additional loading time. For search engines, it creates inefficiency in crawling.
Each step in the chain requires a new HTTP request. On a small scale, this might seem negligible. On a large site, especially one with thousands of URLs, these chains can significantly slow down crawling. Over time, this reduces how frequently search engines revisit important pages, which can affect how quickly updates are indexed.
Chains also complicate signal consolidation. While search engines can follow them, the process is less direct, and there is a higher chance of inconsistencies, particularly if intermediate redirects are changed or removed.
8. Redirects and Crawl Budget Optimization
Redirects and crawl budget are closely linked, especially on large websites where search engines must prioritize which URLs to crawl and how often. Every redirect consumes resources, and when multiplied across thousands of URLs, the impact becomes significant.
When a crawler encounters a redirect, it must make an additional request to reach the final destination. This extra step reduces the number of unique pages that can be crawled within a given timeframe. On smaller sites, this may not be noticeable. On enterprise-level sites, it can limit discovery and delay indexing.
Crawl efficiency is not only about reducing redirects but also about controlling how search engines access different parts of your site. Using directives like robots.txt alongside a clean redirect structure helps ensure that crawlers focus on valuable URLs instead of wasting resources on blocked or unnecessary paths.
Redirect depth also plays a role. A single redirect adds minimal overhead, but chains increase the cost exponentially. Search engines may stop following redirects after a certain threshold, which means deeper chains risk leaving important pages uncrawled.
Even well-implemented redirects cannot compensate for poor internal discovery. Pages that are not linked internally may remain invisible to search engines, regardless of redirect logic. Identifying and fixing orphan pages ensures that valuable URLs are properly integrated into the crawl path and receive consistent indexing signals.
9. Redirect Mapping for SEO Migrations
Redirect mapping is the backbone of any successful SEO migration. Without a structured approach, even small changes can lead to traffic loss, indexing issues, and broken user journeys.
9.1 What is a Redirect Map
A redirect map is a structured document that defines how each old URL corresponds to a new one. It is not simply a list of redirects. It is a strategic blueprint that ensures continuity of signals, relevance, and user experience.
Typically, it includes the original URL, the destination URL, the type of redirect, and notes on content alignment. On large sites, this can scale to thousands or even millions of entries.
9.2 Pre-Migration Redirect Planning
Effective planning begins with a comprehensive URL inventory. This includes all indexable pages, high-value content, and URLs with backlinks. Data is often pulled from crawlers, analytics platforms, and search console tools.
Mapping should prioritize relevance. Each old URL should point to the most contextually similar new page. When no equivalent exists, decisions must be made between redirecting to a broader category, consolidating content, or allowing the URL to return a 404 or 410.
9.3 Execution During Migration
Execution requires coordination between SEO, development, and infrastructure teams. Redirects should be implemented at the server or edge level wherever possible to ensure efficiency.
Deployment sequencing matters. Redirects should be live as soon as the new URLs are accessible. Any delay creates a window where users and crawlers encounter broken pages.
Testing during this phase is critical. Spot checks, automated crawls, and staging environment validation help catch issues before they impact live traffic.
9.4 Post-Migration Validation
Once the migration is live, validation becomes the focus. Crawling the site helps identify broken redirects, chains, and missing mappings. Search console data reveals how indexing is shifting, while analytics platforms provide insight into traffic changes.
Monitoring should continue for several weeks, as search engines gradually process the new structure. Early detection of issues allows for quick corrections, minimizing long-term impact.
10. Redirects vs Canonical Tags vs Noindex: When to Use What
These three mechanisms are often confused, yet they serve fundamentally different purposes. Choosing the right one depends on the outcome you want to achieve.
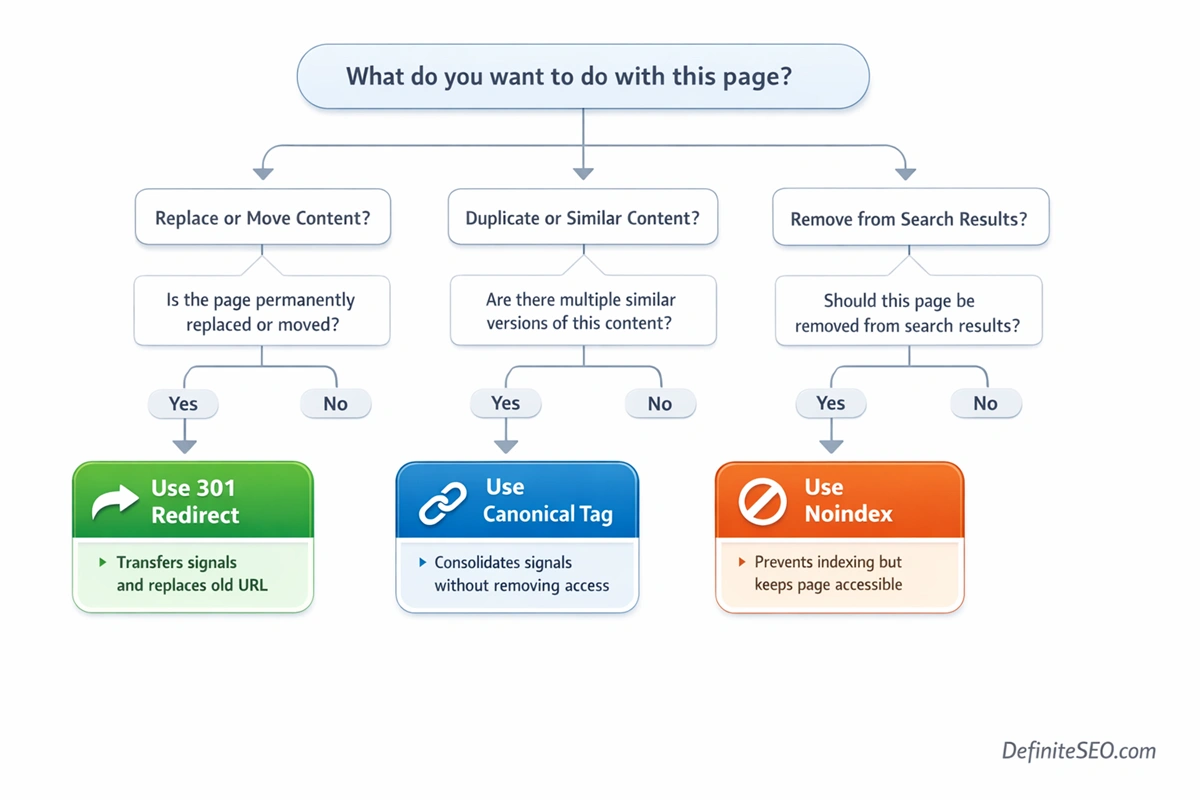
Redirects are the strongest signal. They enforce a change by sending both users and search engines to a new URL. Canonical tags, on the other hand, are hints. They suggest which version of a page should be treated as the primary one, but they do not prevent access to duplicate versions. Noindex directives remove pages from the index without redirecting them elsewhere.
The distinction becomes clearer when viewed through intent. If a page has been permanently replaced, a redirect is appropriate. If multiple versions of similar content exist and you want to consolidate signals without removing access, a canonical tag is the better choice. If a page should not appear in search results at all, noindex is the correct approach.
11. Redirects in JavaScript SEO & Rendering Environments
Modern websites increasingly rely on JavaScript frameworks, which introduces new complexities in how redirects are handled. In traditional setups, redirects occur at the server level. In JavaScript-driven environments, they may occur after the page has been rendered.
Client-side rendering shifts redirect logic into the browser. This means that search engines must first crawl the page, then render it, and only then discover the redirect. This process can delay indexing and introduce inconsistencies, especially if rendering resources are limited.
Server-side rendering offers a more reliable alternative. By handling redirects before the page is delivered, it ensures that both users and crawlers are directed immediately to the correct URL. Frameworks like React and Next.js often support hybrid approaches, allowing developers to choose where redirect logic is executed.
Hydration timing is another factor. If a redirect depends on JavaScript that runs after hydration, there may be a brief period where the original content is visible. This can lead to indexing issues if search engines capture the page before the redirect is triggered.
Google’s rendering queue adds another layer of complexity. Not all pages are rendered immediately. This means JavaScript redirects may not be processed as quickly as server-side ones, particularly on large sites.
Best practices remain consistent. Wherever possible, implement redirects at the server or edge level. Use JavaScript redirects only when necessary, and ensure they are implemented in a way that is consistent and predictable across all environments.
12. International SEO & Redirects
International SEO introduces unique challenges when it comes to redirects, particularly when dealing with multiple languages and regions.
12.1 Geo-Redirects (Automatic Location Redirects)
Geo-redirects automatically send users to a version of the site based on their location. While this can improve user experience, it creates complications for search engines.
Search engine crawlers typically operate from specific locations and may not experience the same redirects as users. This can lead to indexing issues, where certain versions of a site are not discovered or properly understood.
There is also the risk of blocking access to alternative versions. If users are forced into a specific regional version without the option to switch, it can negatively impact both usability and SEO.
12.2 Hreflang vs Redirect Conflicts
Hreflang tags are designed to signal language and regional targeting. Redirects, if not implemented carefully, can override these signals.
For example, if a user requests a French page but is redirected to an English version based on location, it creates a conflict. Search engines may struggle to determine which version should be indexed or served.
This is why hreflang and redirects must be aligned. Each language version should remain accessible, and redirects should not interfere with search engine access.
12.3 Language-Based Redirect Best Practices
A balanced approach is often the most effective. Instead of automatic redirects, many sites use prompts or banners that allow users to choose their preferred version. This preserves accessibility while still guiding users toward the most relevant content.
From an SEO perspective, ensuring that each version is crawlable, properly tagged, and internally linked is more important than enforcing redirects.
13. Mobile SEO and Redirects
Mobile SEO adds another layer of complexity, particularly for sites that still rely on separate mobile URLs.
Historically, many sites used m-dot subdomains and redirected users based on device type. While this approach is less common today, it still exists and requires careful handling.
Incorrect mobile redirects can lead to mismatched content, where users are sent to irrelevant pages. This not only affects user experience but also violates search engine guidelines, which expect parity between desktop and mobile versions.
Dynamic serving offers an alternative, where the same URL serves different content based on device type. This eliminates the need for redirects but introduces its own technical challenges.
14. Redirects and Site Architecture
Redirects have a direct influence on site architecture, often in ways that are not immediately visible. They shape how both users and crawlers navigate through a site.
When internal links point to outdated URLs, redirects act as a bridge. However, over time, this creates a dependency that weakens the overall structure. Instead of a clean, direct architecture, the site becomes layered with indirect pathways.
Updating internal links is just as important as implementing redirects. A well-structured site ensures that all internal navigation points directly to final URLs, reducing reliance on redirects and improving crawl efficiency.
Redirects also play a role during restructuring. When categories are merged or hierarchies are flattened, redirects ensure continuity. At the same time, they must be aligned with the new architecture to avoid creating conflicting pathways.
In structured page hierarchies, redirects must be implemented carefully to avoid disrupting navigation patterns. This is especially important for paginated content, where incorrect redirects can break sequence logic and affect crawl depth. Understanding how pagination works in SEO helps maintain consistency across multi-page structures. See also: pagination SEO.
15. Performance Impact of Redirects
Every redirect introduces an additional step in the loading process. While a single redirect may have minimal impact, multiple redirects can significantly increase latency.
Each HTTP request adds time before the final content is displayed. This affects user experience, particularly on slower networks. It also influences Core Web Vitals, where metrics like Largest Contentful Paint are sensitive to delays in content delivery.
Reducing redirects is one of the simplest ways to improve performance. This involves eliminating unnecessary redirects, consolidating chains, and ensuring that all internal links point directly to final URLs.
16. Common Redirect Mistakes That Kill SEO Performance
Redirects are powerful, but when implemented incorrectly, they can quietly erode rankings, waste crawl budget, and confuse both users and search engines. Most issues are not caused by a lack of knowledge, but by shortcuts taken during migrations, content updates, or CMS changes.
Redirecting to homepage: One of the most damaging mistakes is redirecting all pages to the homepage. This often happens when pages are removed without proper mapping. While it may seem like a safe fallback, it sends a strong signal mismatch. Search engines expect relevance between the original and destination pages. When dozens or hundreds of unrelated URLs suddenly point to a generic homepage, much of the accumulated value is ignored rather than transferred.
Using the Wrong Redirect Type (301 vs 302 Confusion): Misusing 302 and 301 redirects is another recurring issue. Using a 302 for permanent changes can delay signal consolidation, while using a 301 for temporary scenarios can lead to premature deindexing of the original URL. The problem is not just the status code itself, but the intent behind it. Search engines increasingly interpret patterns over time, but inconsistent signals still create ambiguity.
Creating Long Redirect Chains: Broken redirect chains often emerge after migrations. A site may launch with correct redirects, but subsequent updates introduce new layers without removing the old ones. Over time, what started as a clean structure turns into a chain of multiple hops. These chains slow down crawling and dilute signals, especially when they are not regularly audited.
Not Updating Internal Links After Redirects: Ignoring internal link updates is a subtle but impactful mistake. Even when redirects are correctly implemented, internal links should be updated to point directly to final URLs. Otherwise, every internal click or crawl request triggers unnecessary redirects, increasing latency and reducing efficiency.
Redirecting irrelevant content: It is another overlooked problem. When pages are consolidated without considering topical alignment, the resulting redirects may technically work but fail to preserve rankings. Search engines evaluate context, not just structure. If the destination does not match the original intent, the value transfer weakens.
Wildcard redirects: While convenient, can also create unintended consequences. Broad rules that redirect entire patterns of URLs may capture cases that should have been handled individually. This often leads to mismatched destinations, broken user journeys, and loss of relevance signals.
17. Redirect Auditing: Step-by-Step Process
Redirect audits are where theory meets execution. Even well-managed sites accumulate redirect issues over time, which makes regular auditing essential for maintaining performance and crawl efficiency.
17.1 Tools for Redirect Analysis
A comprehensive audit relies on multiple tools working together. Crawlers provide a high-level view of redirect paths, highlighting chains, loops, and incorrect status codes. Browser developer tools allow for real-time inspection of individual requests, which is useful for diagnosing specific issues.
Log analyzers add another layer of depth. They reveal how search engine bots actually interact with redirects, which often differs from what standard crawlers show. This is particularly valuable for identifying patterns such as repeated crawling of outdated URLs or excessive reliance on redirected paths.
No single tool provides the full picture. The combination of crawl data, real user behavior, and bot activity is what leads to accurate insights.
17.2 How to Audit Redirects at Scale
On enterprise-level sites, redirect auditing requires a structured workflow. The process typically begins with a full crawl to map all redirect paths. This is followed by segmentation, where redirects are grouped by type, depth, or impact.
From there, log data is analyzed to validate which redirects are actually being used by search engines. This helps prioritize issues that affect crawl budget and indexing. High-impact pages, such as those with strong backlink profiles or high traffic, are examined more closely.
17.3 Key Metrics to Track
Certain metrics provide a clear picture of redirect health. Crawl depth reveals how many steps it takes to reach a final URL. Response codes indicate whether redirects are implemented correctly. Chain length highlights inefficiencies that need to be addressed.
17.4 Fix Prioritization Framework
Not all redirect issues require immediate action. Prioritization should be based on impact and effort. High-impact issues, such as redirect chains affecting key pages or incorrect redirects on high-traffic URLs, should be addressed first.
Lower-impact issues, such as isolated redirects on low-value pages, can be scheduled for later fixes. This approach ensures that resources are allocated efficiently while still maintaining overall site health.
18. Practical Implementation Examples
Understanding theory is one thing. Applying it correctly requires familiarity with real implementation scenarios across different environments.
18.1 Apache (.htaccess) Examples
In Apache environments, redirects are often managed through the .htaccess file. This allows for precise control over URL behavior at the server level. Rules can be written to handle individual URLs or patterns, ensuring that requests are directed efficiently.
18.2 Nginx Configuration Examples
Nginx uses a different configuration approach, where redirects are defined within server blocks. This setup is typically more performant than .htaccess-based configurations, as rules are processed at the server level without additional file lookups.
18.3 WordPress Plugin Setup
For WordPress users, plugins like DefiniteSEO provide an accessible way to manage redirects without modifying server files. While convenient, these solutions should be used carefully, especially on larger sites, as they operate at the application level and may introduce additional processing overhead.
18.4 Cloudflare Redirect Rules
Cloudflare and similar CDN platforms allow redirects to be handled at the edge. This reduces latency and improves performance, particularly for global audiences. It also enables advanced routing logic without placing additional load on the origin server.
FAQs
How many redirects are too many for SEO?
There is no fixed number, but in practice, more than one redirect between the original and final URL should be avoided. Chains with multiple hops reduce crawl efficiency and can delay signal consolidation.
Do 301 redirects pass full link equity in 2026?
In most cases, 301 redirects pass nearly all link equity. However, the strength of transfer still depends on how relevant the destination page is to the original.
When should I use a 302 instead of a 301?
A 302 should be used when the change is temporary and the original URL is expected to return. Common scenarios include testing, promotions, or short-term maintenance.
Are redirect chains always bad for SEO?
Not always, but they are inefficient. While search engines can follow them, they introduce delays and unnecessary complexity, which can affect both crawling and performance.
Should I update internal links after adding redirects?
Yes. Internal links should always point directly to the final URL. Relying on redirects for internal navigation creates avoidable inefficiencies.
Can redirects affect crawl budget significantly?
Yes, especially on large sites. Each redirect requires an additional request, which reduces the number of pages search engines can crawl within a given timeframe.
What is better: redirect or canonical tag?
It depends on the situation. Redirects enforce a change and are stronger signals, while canonical tags are suggestions used when multiple versions of content need to remain accessible.
How do redirects impact Core Web Vitals?
Redirects add latency by increasing the number of HTTP requests. This can affect metrics like Largest Contentful Paint, especially if multiple redirects are involved.
Are JavaScript redirects safe for SEO?
They can be processed by modern search engines, but they are less reliable than server-side redirects. They should be used only when necessary.
How long should redirects stay in place after migration?
Ideally, redirects should remain indefinitely, especially for URLs with backlinks or historical traffic. Removing them too early can result in lost signals and broken links.