Understanding the difference between noindex and nofollow is fundamental to modern Technical SEO. These two directives directly influence how search engines crawl, index, and evaluate your website’s link structure, yet they are often misunderstood or misapplied. In this comprehensive guide, you’ll learn how noindex and nofollow impact crawl budget, indexation, internal link equity, PageRank flow, and AI-driven search visibility, along with practical strategies to implement them correctly without risking rankings.
Overview
- Why Noindex vs Nofollow Still Confuses SEOs
- Quick Comparison Table: Noindex vs Nofollow at a Glance
- What Is Noindex? (Technical Definition & Search Engine Behavior)
- What Is Nofollow? (Technical Definition & Link Signal Treatment)
- How Google Actually Interprets Noindex and Nofollow in 2026
- Noindex vs Nofollow: Core Differences Explained with Crawling & Indexing Flow Diagrams
- How Noindex Impacts:
- Crawl Budget
- Internal Link Equity
- PageRank Flow
- Sitemap Inclusion
- How Nofollow Impacts:
- External Links
- Internal Links
- Link Equity Distribution
- Spam & UGC Management
- Noindex + Nofollow Together: When (and When Not) to Combine Them
- Meta Robots vs X-Robots-Tag: Implementation Differences
- Noindex in HTTP Headers vs HTML Meta Tags
- How Noindex Interacts with:
- Canonical Tags
- Hreflang
- Pagination
- Faceted Navigation
- Parameter URLs
- Noindex vs Disallow in robots.txt (Critical Differences)
- When to Use Noindex (Strategic Scenarios)
- When to Use Nofollow (Strategic Scenarios)
- When You Should NOT Use Either
- Enterprise SEO Use Cases
- E-commerce Specific Applications
- JavaScript SEO & Rendering Considerations
- How AI Search Engines Interpret Noindex & Nofollow
- Common Implementation Mistakes That Kill Rankings
- Testing & Validation Checklist
- Step-by-Step Implementation Guide (WordPress, Shopify, Custom CMS)
- Real-World Case Studies from DefiniteSEO
- Decision Framework: A Technical Flowchart for Choosing the Right Directive
- FAQs
Why Noindex vs Nofollow Still Confuses SEOs
Few technical SEO topics appear simple on the surface yet create as much silent damage as noindex and nofollow. At first glance, the distinction seems obvious. One controls indexation. The other controls link behavior. Yet in real-world audits, these directives are routinely misapplied, misunderstood, or layered in ways that quietly suppress rankings, dilute link equity, or waste crawl budget.
Part of the confusion stems from history. Early SEO advice treated nofollow as a PageRank sculpting tool. Then search engines changed how they interpreted it. Meanwhile, noindex has always been a directive, but many site owners mistakenly combine it with robots.txt disallow, unintentionally blocking crawlers from seeing the very instruction meant to remove the page from the index.
As search engines evolved from basic crawlers into sophisticated systems powered by machine learning and semantic interpretation, the role of crawl directives also changed. Modern engines like Google do not merely follow instructions blindly. They interpret context, site architecture, link patterns, and intent. That nuance is where many SEOs fall short.
From my experience auditing enterprise websites at DefiniteSEO, I have seen:
- Category pages accidentally noindexed, causing revenue loss
- Faceted navigation mismanaged with nofollow, weakening internal authority flow
- Staging environments leaking into production due to missing noindex
- Global meta directives implemented incorrectly across templates
The issue is not that noindex and nofollow are complex. It is that they sit at the intersection of crawling, indexing, and ranking signals. Misunderstanding that interaction can undermine an otherwise strong SEO strategy.
This guide begins by clarifying the fundamentals with precision, before moving into advanced modeling in later sections.
Quick Comparison Table: Noindex vs Nofollow at a Glance
Before diving deeper, here is a structured overview designed for clarity and AI extraction.
| Factor | Noindex | Nofollow |
|---|---|---|
| Primary Function | Prevents a page from appearing in search results | Instructs search engines not to pass link equity through specific links |
| Affects Crawling? | No, page must be crawled to see the directive | No, links may still be crawled |
| Affects Indexing? | Yes, removes page from index | No, does not remove page from index |
| Affects Link Equity? | Page-level authority may still flow unless combined with nofollow | Reduces or limits link equity passed through marked links |
| Directive or Hint? | Directive | Treated as a hint since 2019 |
| Implementation | Meta robots tag or X-Robots-Tag HTTP header | rel=”nofollow” attribute in links or meta robots |
| Common Use Cases | Thin content, duplicate pages, thank-you pages | Paid links, sponsored links, user-generated content |
| Risk of Misuse | Deindexing valuable pages | Weakening internal linking structure |
What Is Noindex? (Technical Definition & Search Engine Behavior)
At its core, noindex is a robots directive that instructs search engines not to include a specific page in their index. If properly implemented and crawled, the page will not appear in search results.
The most common implementation is through a meta robots tag placed inside the HTML head:
<meta name="robots" content="noindex, follow">
Alternatively, it can be applied via an HTTP response header using the X-Robots-Tag. This method is especially useful for non-HTML files such as PDFs.
From a technical standpoint, an important nuance is often overlooked: a page must be crawled in order for noindex to be processed. If the page is blocked via robots.txt, the crawler cannot see the directive. As a result, the URL may still be indexed based on external signals, but without accessible content.
How Search Engines Process Noindex
The lifecycle generally follows this sequence:
- The crawler discovers the URL.
- The page is crawled and rendered.
- The noindex directive is detected.
- The URL is removed from the index during the next processing cycle.
Removal is not always instant. Depending on crawl frequency and site authority, it may take days or weeks for full deindexation.
Variations of Noindex
Noindex is frequently combined with other directives:
- noindex, follow
- noindex, nofollow
The first allows link equity to pass while preventing the page itself from appearing in search results. The second blocks both indexation and link following.
In practice, noindex, follow is often the safer configuration for low-value pages that still serve as navigational bridges within your internal architecture. Using noindex, nofollow without careful consideration can isolate parts of your site.
One misconception that persists is that noindex eliminates link equity from the page entirely. That is not inherently true. Search engines may continue to evaluate internal links from a noindexed page, depending on broader site signals and crawl persistence.
For a technical breakdown of how directives such as noindex, nofollow, and X-Robots-Tag are interpreted, refer to Google’s official robots meta tag documentation.
What Is Nofollow? (Technical Definition & Link Signal Treatment)
Nofollow is fundamentally different in purpose. Instead of controlling indexation, it influences how search engines treat links.
Originally introduced to combat blog comment spam, the rel=”nofollow” attribute tells search engines not to transfer ranking credit through a specific link.
Example:
<a href="https://example.com" rel="nofollow">Example</a>
Unlike noindex, which applies at the page level, nofollow is typically link-specific. It can also be applied page-wide via meta robots, but that approach is far less common and often discouraged.
From Directive to Hint
In 2019, Google updated how it interprets nofollow. Rather than treating it as a strict directive, it now treats it as a hint. This means:
- The crawler may still follow the link.
- The link may still pass signals in certain contexts.
- The algorithm may override the instruction if deemed appropriate.
This shift fundamentally changed link sculpting strategies. Old-school PageRank manipulation through internal nofollow usage is no longer reliable.
Related Attributes
To refine link intent, Google introduced:
- rel=”ugc” for user-generated content
- rel=”sponsored” for paid links
These attributes help clarify link context rather than simply blocking equity.
How Nofollow Impacts Link Equity
When used appropriately, nofollow can:
- Prevent passing authority to paid or untrusted destinations
- Reduce spam exposure
- Protect outbound trust boundaries
However, excessive internal nofollow usage can fracture your internal linking structure. I have audited sites where entire navigation menus were nofollowed due to CMS defaults. The result was weakened internal authority distribution across core category pages.
How Google Actually Interprets Noindex and Nofollow in 2026
Understanding how Google processes these directives today requires moving beyond definitions and into search engine workflow.
Modern search engines operate in four primary stages:
- Crawl
- Render
- Index
- Rank
Noindex directly affects stage three. If detected, the URL is excluded from the searchable index. However, the page may still be crawled periodically to reassess signals.
Nofollow primarily affects link evaluation between stages one and four. Because it is now treated as a hint, its impact is probabilistic rather than absolute.
Directive vs Hint in Practice
- Noindex remains a directive. When properly crawled, it results in exclusion from search results.
- Nofollow is a hint. Search engines may consider link signals anyway.
This distinction explains why using nofollow to sculpt internal PageRank is unreliable in modern SEO.
Crawl Budget Implications
Noindex does not stop crawling. If a page remains internally linked and valuable for site architecture, it may continue consuming crawl resources. On large websites, this matters.
Nofollow does not inherently conserve crawl budget either. Search engines may still choose to crawl the linked URL.
For enterprise sites, understanding this difference is critical. It affects log file analysis, crawl depth modeling, and large-scale faceted navigation strategies.
Noindex vs Nofollow: Core Differences Explained with Crawling & Indexing Flow Diagrams
To understand the real distinction between noindex and nofollow, you need to visualize how a search engine actually processes a URL. Many explanations stop at definitions. The real clarity comes from mapping each directive to the crawl → render → index → rank pipeline.
![]()
Imagine the workflow like this:
Step 1: Discovery
A URL is discovered via internal links, XML sitemaps, or external backlinks.
Step 2: Crawling
The crawler fetches the page.
Step 3: Rendering
The HTML is processed, JavaScript executed, and directives detected.
Step 4: Indexing Decision
The engine decides whether to store the page in its searchable index.
Step 5: Link Graph Processing
Outbound links are evaluated and added to the link graph.
Now let’s overlay each directive onto this system.
Where Noindex Operates
Noindex acts between Step 3 and Step 4.
- The crawler must first access the page.
- The directive is read during rendering.
- The indexing system then excludes the URL from searchable results.
The page can still exist inside the crawl graph. It can still be requested periodically. It can still influence link relationships. But it does not appear in search results.
This distinction is critical. Noindex controls visibility in the index, not existence in the crawl ecosystem.
Where Nofollow Operates
Nofollow operates during Step 5.
- The page itself can still be indexed.
- The directive influences how outgoing links are treated in the link graph.
- Since it is treated as a hint by Google, link equity may still pass contextually.
This is why saying “nofollow blocks PageRank” is outdated. It modifies link evaluation. It does not function as a hard barrier.
When you map both directives onto the same pipeline, the difference becomes precise:
- Noindex affects whether the page becomes searchable.
- Nofollow affects how links from the page influence other URLs.
They operate in different stages of the algorithmic lifecycle.
How Noindex Impacts Technical SEO Signals
Noindex appears simple. In reality, its ripple effects touch crawl efficiency, link architecture, and consolidation strategy.
Crawl Budget
Noindex does not prevent crawling. If a page remains internally linked or included in your XML sitemap, it can continue consuming crawl budget.
On large sites with tens of thousands of URLs, this becomes significant. In audits, I have seen e-commerce stores with thousands of filtered category URLs marked as noindex but still heavily crawled because they were deeply embedded in navigation.
If your goal is crawl conservation, noindex alone is insufficient. Crawl frequency depends on:
- Internal link prominence
- Historical importance
- External backlinks
- Sitemap inclusion
- Server response stability
A noindexed URL that is strongly linked internally may still receive consistent crawl activity.
Internal Link Equity
One of the most misunderstood areas is whether noindexed pages pass internal authority.
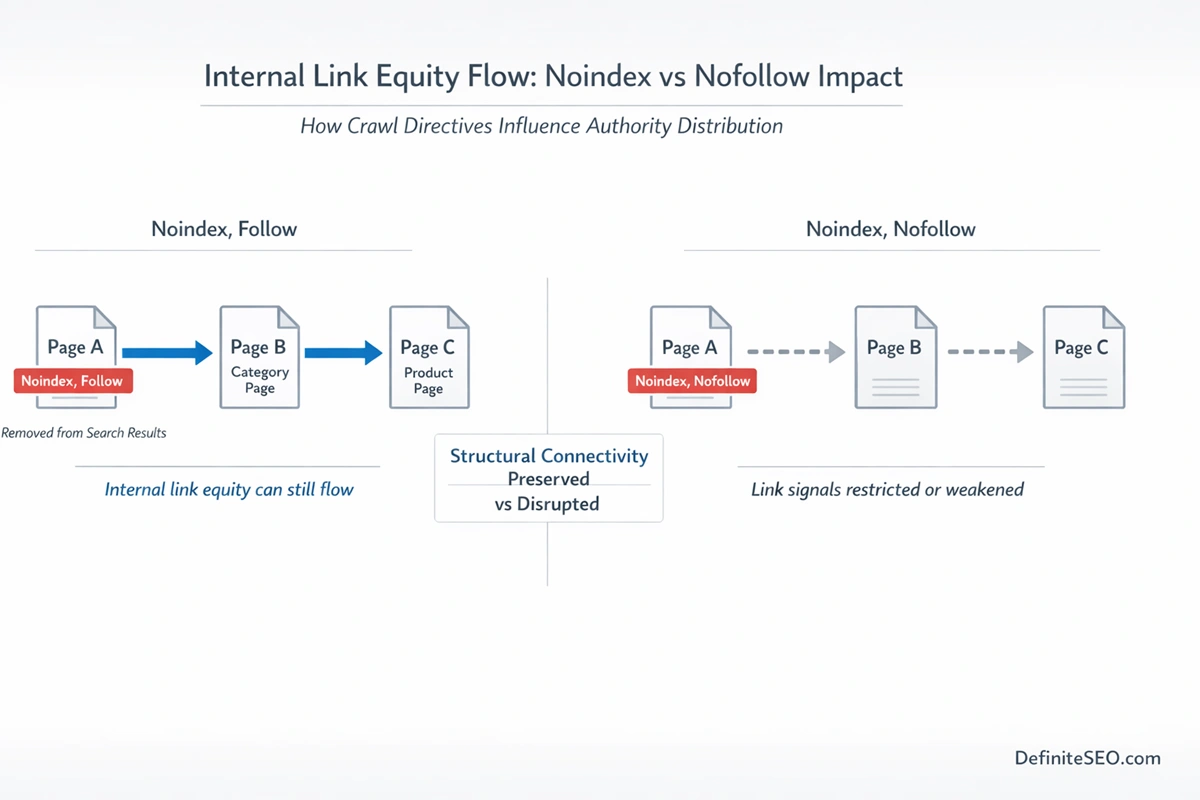
Empirical evidence suggests that search engines can still evaluate and process internal links from noindexed pages. The directive removes the page from search results. It does not automatically sever its link graph relationships.
However, over time, if a page remains noindexed and receives no external signals, its crawl priority may decrease. That indirectly reduces its influence.
Strategically, this means:
- Low-value utility pages can safely use noindex, follow.
- Structural pages that distribute internal authority should not be casually noindexed.
In enterprise audits, the most damaging mistake I encounter is accidental noindex on core category hubs. When those pages are removed from the index, their ranking potential disappears, and internal link consolidation weakens.
PageRank Flow and the Sculpting Myth
Years ago, SEOs attempted to sculpt PageRank by using noindex on unimportant pages to concentrate equity elsewhere. That approach misunderstands modern link evaluation.
If a page is noindexed but still internally linked, its existence in the crawl graph means authority signals are still processed. Removing it from search results does not magically redistribute its weight.
True link equity optimization requires structural clarity, not artificial suppression.
Sitemap Inclusion Strategy
Including noindexed URLs in your XML sitemap sends mixed signals.
Sitemaps communicate index-worthy intent. Noindex communicates the opposite. When both coexist, search engines prioritize the directive but may interpret the sitemap inclusion as inconsistency.
Best practice:
- Remove permanently noindexed URLs from your sitemap.
- Keep temporarily noindexed URLs only if reindexation is planned.
It’ll help strengthen trust signals.
How Nofollow Impacts Link Architecture
Unlike noindex, which is about presence in search results, nofollow reshapes how authority flows across the web and within your own site.
External Links
The most common use case for nofollow is outbound links to untrusted or paid destinations.
Search engines expect:
- Paid placements to use rel=”sponsored”
- User-generated links to use rel=”ugc”
- Untrusted or uncertain links to use rel=”nofollow”
These attributes communicate intent.
Failing to use them can trigger algorithmic distrust. Overusing them, however, can make your link profile appear unnatural or overly cautious.
If you want to understand how rel=”nofollow”, rel=”ugc”, and rel=”sponsored” are evaluated today, review Google’s official guidance on qualifying outbound links.
Internal Links
Internal nofollow is where most architectural damage occurs.
When internal navigation, breadcrumbs, or footer links are nofollowed, you are effectively weakening your own site’s authority distribution model.
Because modern algorithms treat nofollow as a hint, it may not completely block signal flow. But it introduces ambiguity.
Ambiguity in internal linking is rarely beneficial.
If a page is important enough to link to internally, it should usually receive full equity flow. If it is not important, reconsider linking to it at all.
Link Equity Distribution
Nofollow does not preserve PageRank for other links on the page. This is a persistent myth.
Search engines do not redistribute blocked equity proportionally to remaining links. Instead, nofollowed links are simply treated with modified weighting.
In practical terms, excessive nofollow usage can create signal leakage rather than signal concentration.
Spam & UGC Management
For comment sections, forums, and community-driven content, nofollow and rel=”ugc” remain critical.
They:
- Protect your domain from passing equity to spam domains
- Reduce algorithmic association risks
- Clarify editorial responsibility boundaries
However, automated blanket nofollow policies across entire platforms often go too far. Editorially reviewed user contributions may deserve normal link treatment.
Noindex + Nofollow Together: When (and When Not) to Combine Them
Combining noindex and nofollow is technically valid, but strategically delicate.
When both are applied at page level:
<meta name="robots" content="noindex, nofollow">
You are signaling:
- Do not index this page.
- Do not follow its links.
This configuration is appropriate in limited scenarios:
- Staging environments
- Admin portals
- Duplicate technical endpoints
- Temporary internal tools
However, for most public-facing low-value pages, noindex, follow is the safer choice. It removes the page from search results while preserving internal link flow.
Combining both directives on navigational pages can isolate sections of your site. I have seen large websites accidentally apply noindex, nofollow globally via CMS misconfiguration. The result was catastrophic deindexation and structural authority collapse.
Meta Robots vs X-Robots-Tag: Implementation Differences
The technical implementation layer often determines whether directives function correctly.
Meta Robots Tag
Placed in the HTML head:
<meta name="robots" content="noindex, follow">
This is:
- Easy to implement
- CMS-friendly
- Limited to HTML documents
It requires the page to be rendered and parsed.
X-Robots-Tag (HTTP Header)
Implemented at the server level:
X-Robots-Tag: noindex
This method:
- Works for PDFs, images, and non-HTML files
- Does not rely on HTML rendering
- Is ideal for large-scale rule-based implementations
For enterprise sites managing thousands of dynamic URLs, HTTP header directives are often cleaner and more scalable.
A subtle but important difference is visibility. Meta tags are visible in source code. HTTP headers require inspection tools or log analysis to verify.
From an audit perspective, always validate both HTML and header-level directives. Conflicts between them can create inconsistent index behavior.
Noindex in HTTP Headers vs HTML Meta Tags
At a strategic level, noindex is a directive. At an implementation level, it is a technical instruction that must be delivered correctly. The delivery mechanism matters more than most SEOs realize.
There are two primary methods to implement noindex:
- HTML meta robots tag
- HTTP response header using X-Robots-Tag
Both communicate the same directive, yet they operate at different layers of the rendering stack.
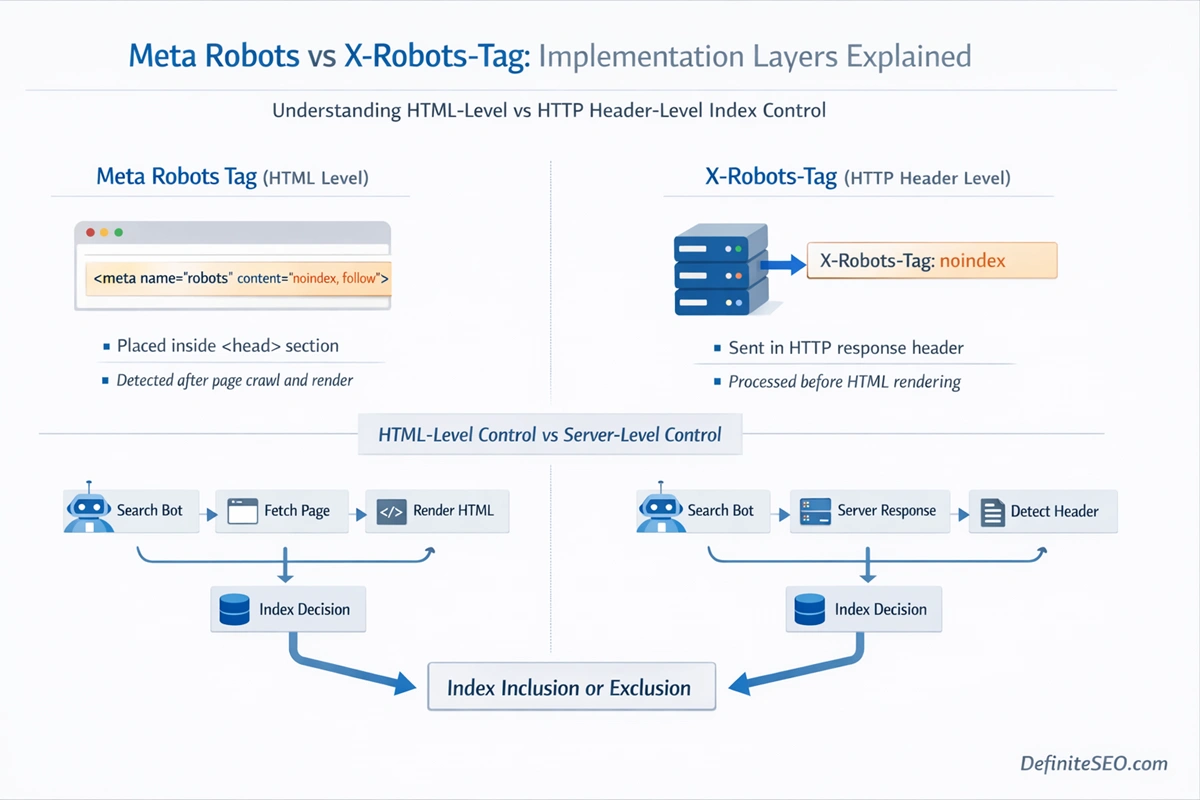
HTML Meta Robots Tag
The HTML implementation sits inside the <head> section of a document:
<meta name="robots" content="noindex, follow">
This method is widely used because it is accessible through CMS settings, SEO plugins, and template files. It works well for standard HTML documents such as blog posts, category pages, landing pages, and product listings.
However, this implementation has limitations.
Search engines must crawl and render the page before detecting the directive. If JavaScript manipulates the head dynamically, the noindex may not be seen immediately. Rendering delays, client-side injection, or hydration issues can interfere with detection.
On JavaScript-heavy websites, especially those using client-side rendering, I have seen cases where the noindex tag was inserted too late in the rendering cycle. The result was unintended indexation.
X-Robots-Tag in HTTP Headers
The HTTP header version looks like this:
X-Robots-Tag: noindex
This directive is sent at the server level before the HTML is even processed. It applies to any file type, including:
- PDFs
- Images
- Video files
- Dynamic endpoints
- API-based content
For enterprise environments, this method offers cleaner scalability. You can define rules at the server or CDN level that automatically apply noindex to entire URL patterns.
It also reduces dependency on front-end rendering.
The difference becomes especially important for non-HTML assets. A PDF cannot contain an HTML meta tag, but it can carry an X-Robots-Tag header.
From an auditing perspective, always verify:
- Page source for meta tags
- HTTP headers using inspection tools
Conflicts between them can create inconsistent signals. If one says index and the other says noindex, search engines generally respect the more restrictive directive, but the inconsistency weakens technical trust.
How Noindex Interacts with Other Technical SEO Signals
Noindex rarely operates in isolation. It interacts with canonical tags, hreflang implementations, pagination structures, faceted navigation systems, and parameter handling. Misalignment between these signals is where most technical SEO damage occurs.
Noindex and Canonical Tags
The canonical tag tells search engines which version of a page should consolidate ranking signals. When combined with noindex, the interaction becomes nuanced.
If a page is marked noindex but also contains a canonical pointing to another URL, search engines may:
- Respect the noindex directive
- Transfer signals to the canonical target
- Eventually drop the noindexed page from the index
However, if the canonical points to itself and the page is noindexed, you are sending conflicting signals. You are essentially saying, “This is the preferred version,” and simultaneously, “Do not index it.”
In practice, noindex typically overrides self-referencing canonicalization. But inconsistent logic can slow processing and reduce clarity.
When consolidation is the goal, canonicalization is usually preferable to noindex. When exclusion is the goal, noindex should stand independently.
Noindex and Hreflang
Hreflang signals international targeting relationships. For hreflang clusters to function properly, pages should generally be indexable.
If you apply noindex to one member of an hreflang set, it disrupts the cluster. Search engines may ignore the noindexed page in the international mapping.
For multilingual or multi-regional sites, this is a common mistake. Development teams sometimes noindex alternate language versions during staging and forget to remove the directive at launch.
If the page should rank in its target country, it must not be noindexed.
Noindex and Pagination
Pagination is structurally important. Applying noindex to paginated pages has been debated for years.
If you noindex deeper pagination pages:
- They may drop from search results.
- Internal product discovery pathways may weaken.
- Crawl frequency may decrease.
However, in some thin archive scenarios, selective noindex may be appropriate.
The key question is intent. Are paginated pages discoverability assets or thin duplicates?
Blanket noindex across pagination without architectural evaluation often creates more harm than benefit.
Noindex and Faceted Navigation
Faceted navigation systems generate large numbers of URL combinations. Here, noindex is frequently used to prevent index bloat.
Yet noindex alone does not reduce crawl volume. If filtered URLs are internally linked or accessible via crawl paths, search engines will continue to explore them.
For large e-commerce sites, combining:
- Controlled internal linking
- Canonicalization
- Parameter handling
- Selective noindex
is usually more effective than relying solely on noindex.
Noindex and Parameter URLs
Parameter-based URLs can create near-duplicate variations. Using noindex for certain parameter combinations may be appropriate, especially for sorting and filtering variations.
However, if parameters significantly change content meaning, canonicalization may be a better solution.
Overuse of noindex for parameter control can mask structural inefficiencies instead of solving them.
Noindex vs Disallow in robots.txt
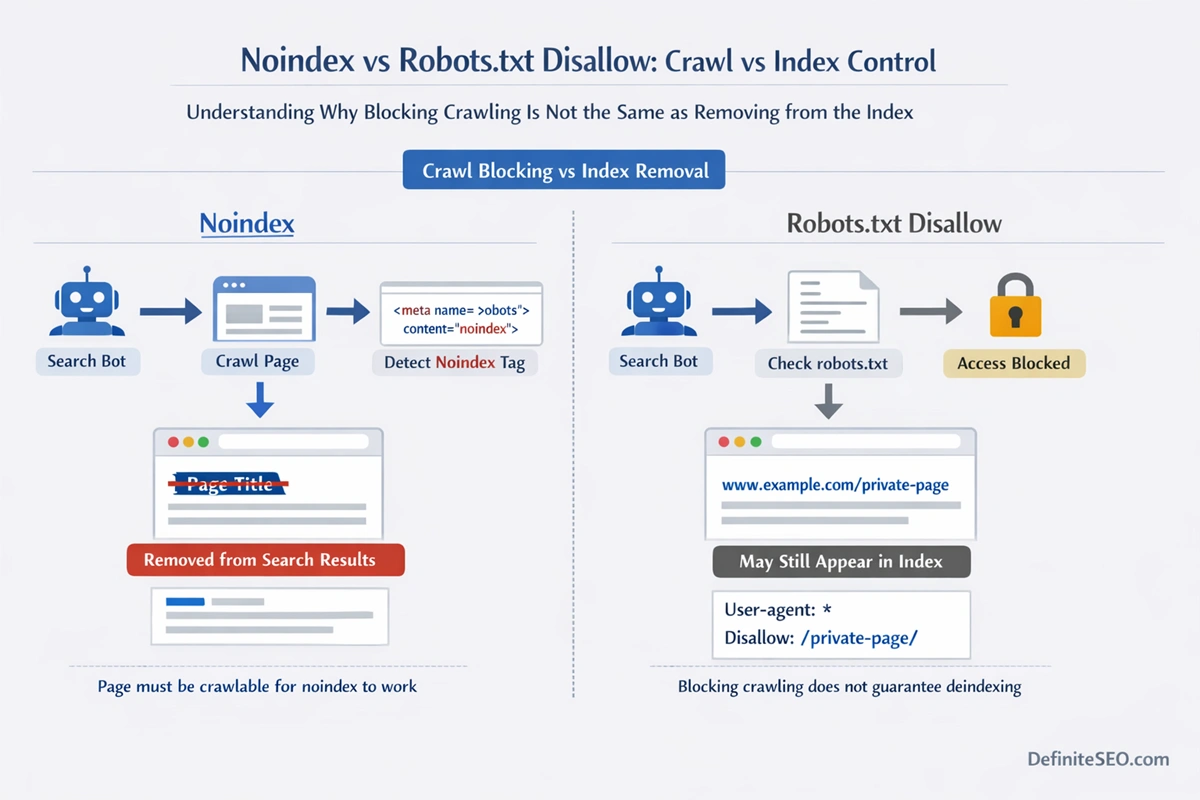
One of the most persistent misconceptions in technical SEO is that disallowing a URL in robots.txt removes it from search results.
It does not.
The robots.txt file controls crawling, not indexing.
If you block a page like this:
User-agent: *
Disallow: /private-page/
Search engines cannot crawl the page. But if external links point to it, the URL may still appear in search results as a bare listing without content.
In contrast, noindex explicitly instructs removal from the index, but requires the page to be crawlable.
This creates a critical implementation rule:
If you want a page removed from search results, do not block it in robots.txt before Google processes the noindex directive.
First allow crawling. Let the noindex be detected. Once removed, you can consider crawl blocking if appropriate.
Misalignment between robots.txt and noindex is responsible for many persistent indexation issues in Search Console reports.
When to Use Noindex (Strategic Scenarios)
Noindex should be applied strategically, not reflexively. The goal is to preserve index quality while maintaining structural integrity.
Common legitimate use cases include:
Thank-you and confirmation pages. These serve functional purposes but offer no search value.
Internal search results pages. Most search engines discourage indexing them.
Thin tag archives. If they offer little unique value, selective noindex can improve overall site quality signals.
Filtered category variations that do not provide meaningful differentiation.
Staging environments and pre-launch pages.
Outdated promotional landing pages that must remain accessible but should not rank.
The guiding principle is this: if the page does not deserve to rank independently, yet still serves user or architectural utility, noindex is appropriate.
However, avoid using noindex as a band-aid for deeper structural problems. If large portions of your site require noindex, the issue may be taxonomy or navigation design.
When to Use Nofollow (Strategic Scenarios)
Nofollow operates at the link level and should communicate editorial intent.
Appropriate use cases include:
Paid and sponsored links. These should ideally use rel=”sponsored”.
User-generated content such as comments or forum posts, especially when moderation is limited.
Untrusted external resources where you do not want to transfer authority.
Affiliate links that may be perceived as commercial endorsements.
Temporary or uncertain outbound references.
What should generally be avoided is large-scale internal nofollow. If a page is important enough to link internally, it should typically receive full signal flow.
When You Should NOT Use Either
In technical SEO, restraint is often more powerful than intervention. Not every low-performing page needs a noindex tag. Not every outbound link needs nofollow. In fact, overusing either directive can quietly erode your site’s authority, crawl efficiency, and structural clarity.
You should not use noindex on pages that:
- Serve as primary category hubs
- Act as internal authority distribution layers
- Target commercial or transactional intent
- Form part of your topical silos
Removing such pages from the index weakens your semantic footprint. Search engines evaluate topical depth at the cluster level. If your category pages disappear from the index, your content ecosystem becomes fragmented.
Similarly, you should not use nofollow on:
- Core internal navigation links
- Breadcrumbs
- Contextual internal links inside pillar content
- High-value editorial outbound references
Internal linking is not just about discoverability. It is about reinforcing topical relationships and consolidating entity associations. When internal links are nofollowed, you introduce uncertainty into your own architecture.
There is also a broader principle at play. Search engines like Google reward clarity. Overuse of crawl directives signals confusion rather than control.
If your instinct is to apply noindex or nofollow widely, pause and ask a more fundamental question: is this a structural issue instead of a directive issue?
In many audits, I have found that taxonomy restructuring produces stronger results than mass deindexation. Architecture solves what directives merely suppress.
Enterprise SEO Use Cases
At enterprise scale, noindex and nofollow evolve from simple page-level decisions into systemic control mechanisms.
Large websites often contain:
- Millions of parameterized URLs
- Dynamic search results
- User account sections
- Regional variations
- API-generated endpoints
In these environments, manual page-by-page control is impossible. Directive logic must be rule-based and scalable.
Large-Scale Index Management
Enterprise platforms frequently generate thin or duplicative URLs through filters, sorting options, and session parameters. Applying X-Robots-Tag headers at the server level can efficiently prevent index bloat without modifying template code.
For example:
- Automatically noindex URLs containing specific query parameters
- Apply noindex to internal dashboards
- Prevent indexation of search-result permutations
The key is aligning directive logic with crawl modeling. Log file analysis often reveals that search engines continue crawling low-value URLs long after they are noindexed. If internal linking continues to expose them, crawl waste persists.
Governance and Risk Mitigation
Enterprise SEO also introduces risk management concerns. A single misconfigured global noindex tag can deindex an entire domain quickly.
During migrations, I have seen staging directives accidentally pushed live, causing widespread index loss. In these environments, directive governance must include:
- Deployment safeguards
- Template-level validation
- Continuous index monitoring
- Automated alerts
E-Commerce Specific Applications
E-commerce websites represent one of the most complex environments for noindex and nofollow strategy. Faceted navigation, product variations, seasonal categories, and dynamic filtering create exponential URL growth.
Product Variations and Filters
A single category page can generate thousands of combinations:
- Size filters
- Color filters
- Price ranges
- Sorting parameters
Blindly indexing all of them leads to index bloat. Blindly noindexing all of them may suppress high-intent search opportunities.
The solution lies in intent modeling.
If a filtered page aligns with meaningful search demand, it may deserve indexation. If it creates thin duplication, selective noindex or canonicalization may be appropriate.
Out-of-Stock Products
When products go out of stock, many stores default to noindex. That is not always optimal.
If the product has historical backlinks or search demand, keeping it indexed while offering alternatives can preserve equity. Removing it may waste accumulated authority.
Noindex should be used only when a page permanently loses value and offers no alternative pathway.
Affiliate and Marketplace Links
E-commerce sites frequently link to external marketplaces, payment gateways, or affiliate partners. In these scenarios, rel=”sponsored” or rel=”nofollow” can clarify commercial intent.
But internal product-to-category links should almost never be nofollowed. Those connections define your commercial architecture.
JavaScript SEO & Rendering Considerations
Modern websites increasingly rely on JavaScript frameworks. This introduces a new layer of complexity for crawl directives.
Search engines must:
- Crawl the raw HTML
- Render JavaScript
- Process dynamically injected meta tags
If noindex is inserted only after client-side rendering, there may be a delay before it is detected.
In extreme cases, rendering failures can result in pages being indexed without the intended directive.
Frameworks using client-side rendering (CSR) must ensure:
- Noindex tags are present in server-rendered HTML where possible
- Hydration timing does not delay directive exposure
- Testing occurs using rendered HTML inspection
Dynamic Rendering and Edge Cases
If a site uses dynamic rendering or edge-level content modification, directives may differ between user agents. Inconsistent directive delivery can erode trust signals.
A page showing index to one user agent and noindex to another introduces ambiguity. Search engines increasingly detect such inconsistencies.
In technical audits, I always recommend validating directives in:
- Raw HTML
- Rendered HTML
- HTTP headers
JavaScript-heavy environments require layered verification.
How AI Search Engines Interpret Noindex & Nofollow
Search behavior has evolved beyond traditional link-based ranking. Generative engines and AI-driven search experiences extract structured data, contextual signals, and indexed content to generate synthesized answers.
If a page is noindexed, it is generally excluded from the searchable corpus that feeds AI answer generation. This has direct implications for visibility in AI summaries and conversational results.
Modern engines like Google increasingly integrate generative overviews that rely on indexed content. A noindexed page is unlikely to be cited or summarized.
This changes the strategic stakes.
Previously, noindex was about SERP visibility. Now it also influences AI discoverability.
Nofollow operates differently. Since it is treated as a hint, outbound link signals may still contribute to contextual association. However, AI-driven systems focus more heavily on content clarity, entity relationships, and structured data.
Overusing nofollow internally can weaken topical connectivity. In AI-driven search, entity coherence matters. If your internal links do not clearly map topical relationships, your site’s semantic graph becomes fragmented.
Common Implementation Mistakes That Kill Rankings
Most ranking losses tied to noindex and nofollow are not algorithmic penalties. They are self-inflicted technical wounds. In many audits I’ve conducted, the damage was not caused by Google updates but by small directive misconfigurations that quietly compounded over time.
One of the most destructive mistakes is the accidental global noindex. This often happens during development. A staging site is correctly marked noindex to prevent premature indexation. Then, during deployment, that directive remains active. Within weeks, critical category and product pages disappear from search results. Traffic drops, rankings collapse, and the root cause sits unnoticed in the page template.
Another recurring issue is combining noindex with robots.txt disallow in the wrong order. When a page is blocked in robots.txt, crawlers cannot access the HTML. If a noindex directive is present in the HTML, it will never be seen. The URL may remain indexed as a bare listing because the crawler cannot verify its status. This contradiction creates persistent “Indexed, though blocked by robots.txt” errors in search console reports.
Internal nofollow misuse is another silent killer. I have audited sites where navigation links were automatically assigned rel=”nofollow” due to a CMS setting intended only for external links. Over time, core category pages received diluted internal authority, weakening their ability to rank competitively.
Self-referencing canonical combined with noindex is also problematic. When a page declares itself canonical but simultaneously instructs search engines not to index it, the signals conflict. Search engines tend to respect noindex, but the inconsistency reduces processing efficiency.
Enterprise platforms often introduce header-level X-Robots-Tag rules that override page-level meta tags. If teams are unaware of server-level directives, debugging becomes complex. One system says index. Another says noindex. The more restrictive directive typically wins, but the inconsistency erodes clarity.
JavaScript frameworks add another layer of risk. If noindex is injected client-side and fails to render properly for crawlers, unintended indexation can occur. Rendering diagnostics become essential in such environments.
The pattern behind all these mistakes is the same. Directive implementation is treated as a checkbox rather than a strategic decision. Technical SEO requires coordination between developers, content teams, and SEO leadership. Without governance, small configuration errors scale into systemic ranking losses.
Testing & Validation Checklist
Directive implementation should never rely on assumption. Every noindex or nofollow decision must be validated across multiple layers of the crawl and indexing process.
First, verify that the directive exists where expected. Inspect the page source or use an online website audit tool to confirm the meta robots tag appears correctly formatted. Then check HTTP response headers to ensure there are no conflicting X-Robots-Tag rules.
Next, use URL inspection tools to confirm how search engines interpret the page. Does the crawler detect the noindex directive? Is the page eligible for indexing? Is it currently indexed? These questions matter more than simply confirming that a tag exists in the HTML.
Log file analysis adds another layer of insight. Even after a page is noindexed, is it still being crawled frequently? If so, internal linking may be sustaining crawl demand. In enterprise environments, crawl behavior often tells a more accurate story than search console reports alone.
For nofollow validation, inspect both link-level attributes and site-wide patterns. Ensure that rel=”nofollow” is not being injected unintentionally into internal navigation. Review templates, not just individual pages.
Step-by-Step Implementation Guide (WordPress, Shopify, Custom CMS)
Implementation differs across platforms, but the strategic logic remains consistent.
WordPress
On WordPress, noindex is typically managed via SEO plugins or theme settings. Most major WordPress SEO plugins like DefiniteSEO allow page-level control where you can toggle index or noindex for individual posts, categories, and taxonomies.
When applying noindex:
- Confirm the setting generates a proper
<meta name="robots" content="noindex, follow">tag. - Clear caching layers to ensure the directive is visible.
- Validate through source inspection and URL inspection tools.
- Remove permanently noindexed URLs from your XML sitemap.
For nofollow, use rel attributes on outbound links. Avoid global filters that add nofollow to all internal links.
Shopify
Shopify presents different challenges. Direct template editing is often required for advanced control.
For filtered collections or parameter-based URLs, selective noindex may require:
- Editing theme.liquid or collection templates
- Implementing conditional meta tags
- Leveraging Shopify apps cautiously
Shopify automatically generates certain URL variations. Rather than applying blanket noindex, evaluate whether canonicalization provides a cleaner solution.
External affiliate links within product descriptions can use rel=”sponsored” or rel=”nofollow” where appropriate.
Custom CMS or Enterprise Platforms
Custom environments often benefit from server-level X-Robots-Tag rules. This is especially efficient for:
- Parameterized URLs
- Non-HTML files
- Large-scale rule-based logic
Implementation should follow a structured process:
- Define URL patterns that require control.
- Implement header-level directives where scalable.
- Validate via header inspection tools.
- Monitor index coverage over subsequent crawl cycles.
In enterprise systems, coordination between SEO and development teams is essential. Directive logic should be documented and version-controlled to prevent accidental reversals during deployments.
Real-World Case Studies(by Param Chahal)
Directive strategy is not theoretical. Its impact can be measured.
Case Study 1: Faceted Navigation Cleanup
An e-commerce client with over 250,000 URLs was experiencing crawl inefficiency. Thousands of filtered URLs were indexed, many with thin content. Rankings for core categories stagnated.
Rather than mass-disallowing URLs in robots.txt, I:
- Identified low-value parameter combinations
- Applied selective noindex via server-level rules
- Cleaned internal linking pathways
- Removed noindexed URLs from sitemaps
Within three months, crawl frequency shifted toward primary category pages. Core rankings improved, and index coverage stabilized. The improvement was not immediate, but it was durable.
Case Study 2: Accidental Global Noindex
A mid-sized SaaS company experienced a sudden 70 percent traffic drop. Investigation revealed that during a redesign, a global noindex tag remained active across all templates.
Once corrected and resubmitted for indexing, rankings gradually returned. However, recovery took weeks because crawl recency varied by page importance. High-authority pages recovered first. Deeper pages lagged.
Case Study 3: Internal Nofollow Overuse
A content publisher applied nofollow to all outbound links, including internal cross-links, due to a plugin misconfiguration. Internal authority distribution weakened significantly.
After removing internal nofollow attributes and restoring clean linking pathways, ranking stability improved over the following quarters. The fix did not create an overnight surge, but it restored architectural clarity.
A Technical Framework for Choosing the Right Directive
Choosing between index, noindex, follow, and nofollow should not be emotional. It should be logical.
Start with a fundamental question: Should this page appear in search results?
If the answer is yes, do not apply noindex.
If the answer is no, ask a second question: Does this page serve an internal navigational or authority-distribution purpose?
If yes, use noindex, follow.
If no, and the page is purely functional or isolated, noindex, nofollow may be appropriate.
Next, evaluate outbound links. Is the link paid, sponsored, or user-generated without editorial oversight?
If yes, use rel=”sponsored” or rel=”ugc” as appropriate. If uncertain, rel=”nofollow” remains a safe boundary marker.
If the link is editorially placed and relevant, do not restrict it unnecessarily. Trust signals work both ways.
Finally, consider crawl efficiency. If your concern is crawl waste rather than index bloat, evaluate architecture before directives. Blocking discovery pathways often produces better results than suppressing pages post-crawl.
FAQs
Can Google index a page that has a noindex tag?
If the page is crawlable, Google can temporarily keep it in the index, but once the noindex directive is processed, it will eventually be removed.
How long does it take for a noindexed page to disappear from search results?
Deindexing can take a few days to several weeks depending on crawl frequency, site authority, and internal linking strength.
Does noindex stop a page from passing link equity internally?
Noindex removes the page from search results but internal links may still be evaluated and processed within the site’s link graph.
Does nofollow prevent Google from crawling a link?
Nofollow is treated as a hint, so Google may still crawl the link if it finds strong signals to do so.
Should I noindex paginated pages?
Only if the paginated pages provide no independent search value; otherwise, keeping them indexable can support deeper product or content discovery.
Can I use canonical and noindex together?
Yes, but the signals must align logically; otherwise, noindex will typically override indexation even if a canonical is present.
Is it better to use noindex or disallow in robots.txt for removing pages?
Noindex is more reliable for removal because robots.txt disallow blocks crawling but does not guarantee deindexation.
Should internal links ever use nofollow?
In most cases no, because internal nofollow weakens architectural clarity and authority distribution.
Do AI search engines access noindexed pages?
If a page is not indexed, it is generally excluded from searchable corpora used by AI-driven summaries.
Does nofollow protect my site from penalties?
Nofollow helps signal non-endorsement of paid or untrusted links, but overall site quality and editorial standards remain more important.